一、小程序赚钱逻辑我们平时看到或者用过的微信小程序,背后都是有着公司和个人开发者运作,很多人以为小程序只有技术人员才能做,其实人人都可以注册小程序截至目前微信小程序开发者已经突破 300 万,相信只要学习上架步骤和有现成的源码, 人人都可成为小程序开发者。
当小程序积累 1000 用户后(用户点进来算新用户),就可以开通流量主,流量主是腾讯为小程序开发者提供的一种变现方式流量主简单来说就是在小程序中加入广告,每当有用户访问小程序后,就能收到广告收益 在小程序中为开发者提供了九种广告(只需要了解即可)。
其中,格子广告、视频广告都可以用原生模板广告代替,可以战术性略过开屏广告,也即是进入小程序之前展示的开屏广告,该广告无需改动代码, 在后台开启即可插屏广告,就是小程序中的弹窗广告,和一些 app 中的类似。
激励视频广告,顾名思义,在小程序中要获得一些资源时,看完广告才能获得例如,你是一个电商小程序,看广告可以领取优惠劵,这采用激励视频就是最合适的原生模板广告,可以在开发者后台自定义广告大小和颜色,灵活性最高的 一种广告。
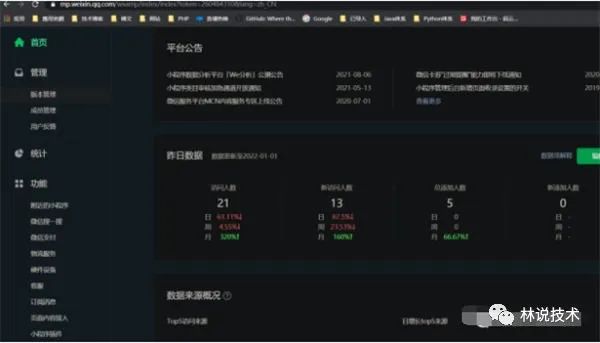
有了这些广告形式,我们可以自主的在小程序中添加这些广告,从而给我们带来被动收入。下图为我其中一个小程序去年的收入,从流量主数据助手中可以清晰的看到每个广告位为自己带来了多少收益。
二、搭建上架小程序首先要拥有一个自己的小程序账号,就像你拥有一个微信号一样百度搜索-微信公众平台,进入官网-点击注册,显示官方的点进去注册一个小程序就像注册一个微信一样简单,填写完基本信息,通过以后就可以进入小程序的管理后台。
左侧是小程序后台的菜单。
一直拉到菜单最下面,点击设置把小程序的相关信息填写一下首先,第一个比较重要的点就是给小程序起名,起名这件事很玄学自然流量是一个很重要的一个流量渠道,什么是自然流量呢?就是在直接微信搜索进来的用户, 有一个好的名字是非常重要的(具体看第三部分),其他的待填项自由发挥,服务类目选择办公-工具。
信息填写完成之后,会有一个 AppID(就像是你的微信号),这个 AppID 很重要,在创建项目和项目上线都是需要的(最好复制保存到一个地方)。

经历了这些步骤以后,小程序就注册完成了,应该也是最繁琐的一个步骤了接着安装小程序开发的工具-微信开发者工具,百度搜索微信开发者工具,点击 下载(找官网...官方下载),选择对应的系统安装,应该大部分人都是选择 Windows 64。
就像安装别的电脑软件一样简单,一路点击下一步、下一步.....安装打开以后,会看到下面的界面
AppID 填写后台的那个 AppID,后端服务选择-不使用云服务,然后确定在目录中选择小程序源码,我目前开源了三套源码,想尝试的圈友可以选择感兴趣的下载骰子源码:链接:https://pan.baidu.com/s/1pTOowpC66RbTpi3Px89V7A?pwd=tian 提取码:tian。
链接:https://pan.baidu.com/s/1rZjXcNuG3echZbc3avjZDA?pwd=tian 提取码:tian国庆头像源码:链接:https://pan.baidu.com/s/1gXaKD55BfjdFZiO4yPksXA?pwd=tian 提取码:tian
我们以骰子源码为例,下载到源码到本地以后, 导入开发者工具就看到一个酷炫小程序了,可以在开发者工具里面点击预览下效果,到这里就基本成功了。
点击右上角的上传按钮,等待几分钟后回到小程序的后台-版本管理这时候在后台就可以看到开发版本了,如果找不到的话,不用猜,你一定是把 AppId 填错了,再重复导入源码步骤既可然后点击提交审核,点击前可以先预览一下体验版,点击提交审核旁边的倒箭头, 微信扫码既可预览体验版。
审核大约半小时左右就可以通过了审核通过以后微信官方会消息的,要回到后台点击发布哦,要不然是找不到的等几分钟在微信里面搜索,看下能不能搜到吧,如果还不能搜到就再多等几分钟小程序搭建只是做好了基础设施,决定你每天收入的重要部分来啦。
三、引流小程序流量有两个主要来源,一个是主动推广,另一个是自然流量当用户在微信搜索小程序时,微信首先根据名字的匹配度查询出来一堆小程序,用户使用过的小程序会优先排在最前面,再后面优先根据小程序权重排名,微信官方有一个好用的工具—微信指数,微信指数会用折线图显示最近某个词的热度。
我们要做的就是使用微信指数不断的改名,改名成功以后,我们给它一周的时间,看它的自然流量会不会稳步增长,如果流量仍然是一潭死水,就继续换名字,直到将改名次数用完有时候可能你的自然流量不上不下,你就会陷入到一个犹豫之中,我还要不要继续改名?再改名会不会还不如这个名字? 其实这在你犹豫时已经有了答案,既然犹豫就是对你现在的名字不满意,我的建议是继续换。
不换只会让你后悔,根据我的经验来看名字都是越改越好,流量也是越来越高, 改一次名字就会给你带来新的可能,小程序起名就是选高频词,自然流量都是在一步步的优化中实现的当你发现一个词流量不错,你就接着注册新的小程序,围绕这个词上新小程序, 没有新的源码就复用老代码。
这是小程序自然流量的核心,而主动推广就需要借助其他流量平台的协助,陷于篇幅,下篇文章再带大家一步步解读
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。