梯度下降是一种常用的优化算法,它通过不断迭代来最小化一个损失函数根据不同的损失函数和迭代方式,梯度下降可以被分为批量梯度下降(Batch Gradient Descent,BGD)、随机梯度下降(Stochastic Gradient Descent,SGD)、小批量梯度下降(Mini-batch Gradient Descent)、共轭梯度法(Conjugate Gradient,CG)等。
1、批量梯度下降(Batch Gradient Descent,BGD)批量梯度下降(Batch Gradient Descent,BGD)是一种非常常见的梯度下降算法,它通过在每一次迭代中计算所有训练样本的梯度来更新模型参数。
其具体算法参见上一篇博文:线性回归 梯度下降原理与基于Python的底层代码实现GD 的优点包括:可以保证收敛到全局最优解,特别是在凸优化问题中可以利用矩阵运算,加速计算过程对于比较稠密的数据集,BGD 的计算速度较快。
BGD 的缺点包括:需要处理所有训练样本,计算量较大,因此不适合处理大规模数据集可能会陷入局部最优解,特别是在非凸优化问题中对于比较稀疏的数据集,BGD 的计算效率较低,因为大部分数据都是无关的由于每次迭代都需要处理整个数据集,因此在处理在线学习或实时学习等实时数据流问题时,BGD 的计算效率也较低。
2 、随机梯度下降(Stochastic Gradient Descent,SGD)随机梯度下降(Stochastic Gradient Descent,SGD)是一种常用的梯度下降算法,它通过在每一次迭代中计算一个训练样本的梯度来更新模型参数。
SGD 的优点包括:可以处理大规模、稀疏或实时数据流问题,因为每次只处理一个样本,计算效率较高可以跳出局部最优解,因为每次更新参数的方向不一定是相同的对于非凸优化问题,SGD 的表现可能会更好,因为它能够跳出局部最优解。
SGD 的缺点包括:可能无法保证收敛到全局最优解,因为更新方向是随机的在处理比较稠密的数据集时,SGD 的计算速度可能较慢,因为需要频繁读取数据可能会出现震荡或抖动的情况,导致收敛速度较慢随机梯度下降算法适合处理大规模、稀疏或实时数据流问题,并且能够跳出局部最优解。
但是,对于小规模、稠密或需要保证全局最优解的问题,SGD 的表现可能会不如批量梯度下降算法同时,SGD 的收敛速度可能会受到震荡或抖动的影响,需要进行一些额外的优化或调整3、小批量梯度下降(Mini-batch Gradient Descent, MGD)
小批量梯度下降(Mini-batch Gradient Descent,MBGD)是一种介于批量梯度下降(Batch Gradient Descent,BGD)和随机梯度下降(Stochastic Gradient Descent,SGD)之间的梯度下降算法,它通过在每一次迭代中计算一小部分训练样本的梯度来更新模型参数。
MBGD 的优点包括:可以利用矩阵运算,加速计算过程对于比较稠密的数据集,MBGD 的计算速度较快对于比较稀疏的数据集,MBGD 的计算效率也比较高可以保证收敛到全局最优解,特别是在凸优化问题中可以跳出局部最优解,因为每次更新参数的方向不一定是相同的。
MBGD 的缺点包括:需要手动设置小批量大小,如果选择不当,可能会影响收敛速度和精度对于大规模、稀疏或实时数据流问题,MBGD 的计算效率可能不如 SGD,但比 BGD 要好小批量梯度下降算法是一种折中的梯度下降算法,可以在一定程度上平衡计算效率和收敛速度,适用于大部分深度学习模型的训练。
但是,需要根据具体情况来选择小批量大小,以获得最好的效果4、共轭梯度法(Conjugate Gradient,CG)共轭梯度法(Conjugate Gradient,CG)是一种针对特殊的矩阵结构进行求解的迭代方法,它可以快速收敛到全局最优解。
CG 方法是一种迭代算法,每次更新的方向不同于梯度方向,但会沿着前一次更新方向和当前梯度方向的线性组合方向进行更新CG 算法的迭代过程可以描述为以下步骤:随机初始化模型参数计算梯度,并将其作为初始搜索方向。
沿着搜索方向更新模型参数计算新的梯度,并计算一个新的搜索方向,使得该方向与前一次搜索方向共轭重复步骤 3-4,直到达到预定的迭代次数或误差阈值CG 算法的优点包括:可以快速收敛到全局最优解,特别是对于对称、正定的矩阵结构而言。
不需要存储所有历史梯度,可以节省内存空间在更新模型参数的方向上,CG 方法不需要进行线搜索,因此不需要设置学习率等参数CG 算法的缺点包括:只适用于特定类型的矩阵结构,特别是对称、正定的矩阵结构而言对于非凸优化问题,CG 的表现可能会不如其他梯度下降算法。
由于需要额外的内存来存储一些临时变量,因此在处理大规模问题时可能会受到限制共轭梯度法适用于对称、正定的矩阵结构,可以快速收敛到全局最优解,并且不需要进行线搜索但是,对于非凸优化问题和大规模问题,CG 的表现可能会受到一些限制。
5 不同梯度方法的底层代码实例5.1 构造数据集此处我们假定数据集仅x一个变量,x与y的关系为y = 8 x y=8xy=8x下面将构造100个数据,x的取值范围为range(0, 10, 0.1)

此处EXAMPLE_NUM为数据个数;BATCH_SIZE为小批量梯度下降每次使用的数据个数;TRAIN_STEP为迭代次数;X_INPUT为构造的x取值范围;Y_OUTPUT_CORRECT为对应的y真实值,这里根据xy的映射关系,在数据集上加入了(-10,10)的噪音。
同时构造了train_func,用于后面梯度下降寻找最佳k值的使用5.2 BGD回归
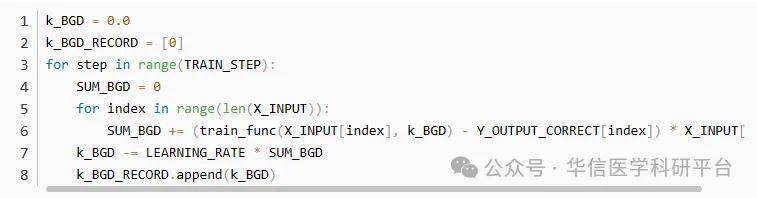
k_BGD为给定的初始k值,k_BGD_RECORD用于记录梯度下降过程中K值的变化第一个循环为在150次训练中的循环,第二个循环为依次计算每一个数据的梯度,并将所有计算结果求和这里SUM_BGD为损失函数的导数。
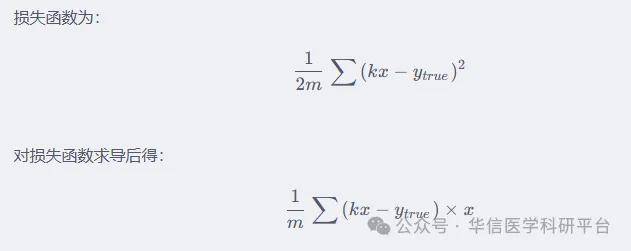
在代码中没有写出,是因为其本身也是一个常数,可以整合到学习速率之中。(因此相比于随机梯度下降,批量梯度下降的学习速率可以小一些,否则会学习过快)5.3 SGD回归
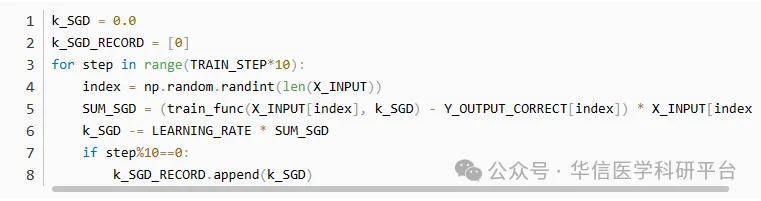
SGD就只有一个循环了,因为SGD每次只使用一个数据,同时考虑到训练速度,对其训练周期进行了10倍扩增每计算一个数据的梯度之后,都会对k进行更新由于k的更新较慢,因此我们采取每隔10次才记录一次k的变化值。
5.4 MGD回归
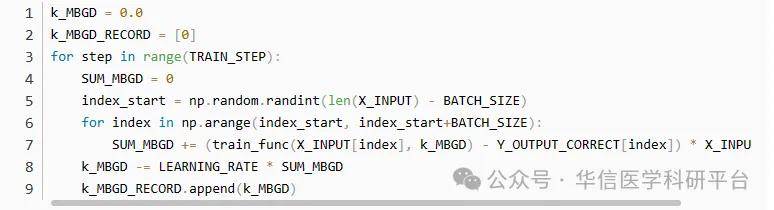
MGD与BGD的代码很类似,只是每个step的数据只有BATCH_SIZE个需要注意在随机选择数据起点时,其范围是0至len(X_INPUT) - BATCH_SIZE,以免数据的选择范围超出数据量5.4 不同方法的对比绘图


可以看到BGD的训练效果最快,这是因为BGD的数据量比另外两种多了10倍通常情况下,BGD的曲线会更加平滑,另外两种方法会有偶尔的偏离正确值的情况但BGD无法避开局部最优,由于本函数不存在局部最优,因此三种效果的拟合方法都还不错。
返回搜狐,查看更多责任编辑:
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。



发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。