商业秘密泄露的方式有哪些?如何防止商业秘密泄露?在日益激烈的市场竞争中,商业秘密作为企业的重要资产,其保护显得尤为重要然而,商业秘密的泄露却时有发生,给企业的正常运营和市场竞争带来极大的威胁本文将探讨商业秘密泄露的渠道
、影响,以及如何通过安企神软件来有效防止商业秘密的泄露。

商业秘密泄露的方式有哪些?如何防止商业秘密泄露?一、商业秘密泄露的渠道商业秘密的泄露渠道多种多样,包括但不限于以下几种:1、员工泄密: 离职或在职员工受不当利益驱使,可能将商业秘密泄露给竞争对手2、外部间谍:。
一些公司利用工业间谍非法获取竞争对手的商业秘密,以达到商业目的3、对外交流: 在接待外来人员采访、参观、考察、实习等过程中,企业可能疏忽大意,导致商业秘密泄露4、供应链泄露: 企业与供应商、客户之间的合作中,也可能导致商业秘密的泄露。
5、公开渠道: 如技术著述的公开发表和演讲等,也可能间接泄露商业秘密。

商业秘密泄露的方式有哪些?如何防止商业秘密泄露?二、商业秘密泄露的影响商业秘密的泄露会给企业带来严重的影响,包括但不限于:1、经济损失: 商业秘密的泄露可能导致企业失去市场优势,造成经济损失2、声誉损害:。
泄露事件可能损害企业的品牌形象和声誉,影响企业的市场地位。3、法律风险: 泄露商业秘密可能违反法律法规,使企业面临法律诉讼和处罚。

商业秘密泄露的方式有哪些?如何防止商业秘密泄露?三、安企神软件防止商业秘密泄露的解决方案针对商业秘密泄露的问题,安企神软件提供了一套全面的解决方案,帮助企业有效防止商业秘密的泄露1、文档加密: 安企神软件采用国际先进的加密算法,对文件进行全面加密,确保数据在存储、传输和使用过程中的安全。
2、上网行为审计: 软件能够实时监控员工的上网行为,包括搜索、聊天、上传下载、邮件等,防止员工泄露商业秘密3、本地应用管控: 为程序设置黑白名单,防止员工下载无关软件,禁止员工下载新软件以及卸载软件,保护电脑安全。
4、远程运维管理: 软件支持远程协助和实时屏幕监控,帮助管理员实时了解员工的工作状态,发现问题及时解决。

商业秘密泄露的方式有哪些?如何防止商业秘密泄露?四、安企神软件的防泄密功能安企神软件具有以下防泄密功能:1. 全方位加密保护: 采用先进的加密算法,对文件进行全面加密,确保数据在存储、传输和使用过程中的安全。
2. 细粒度权限管理: 根据岗位和职责,为每位员工设定不同的文件访问权限,有效防止敏感数据被不当访问3. 日志审计与监控: 详细记录员工的文件操作行为,及时发现潜在的安全风险,为事后追溯提供有力证据4、文件加密
:对文件进行加密保护,确保数据安全5、USB设备管理 :控制USB设备的使用权限,防止数据通过移动存储介质泄露6、打印控制 :限制对敏感文件的打印和复制,防止纸质文件泄露7、行为审计 :记录用户对文件的操作行为,便于追溯和审计。
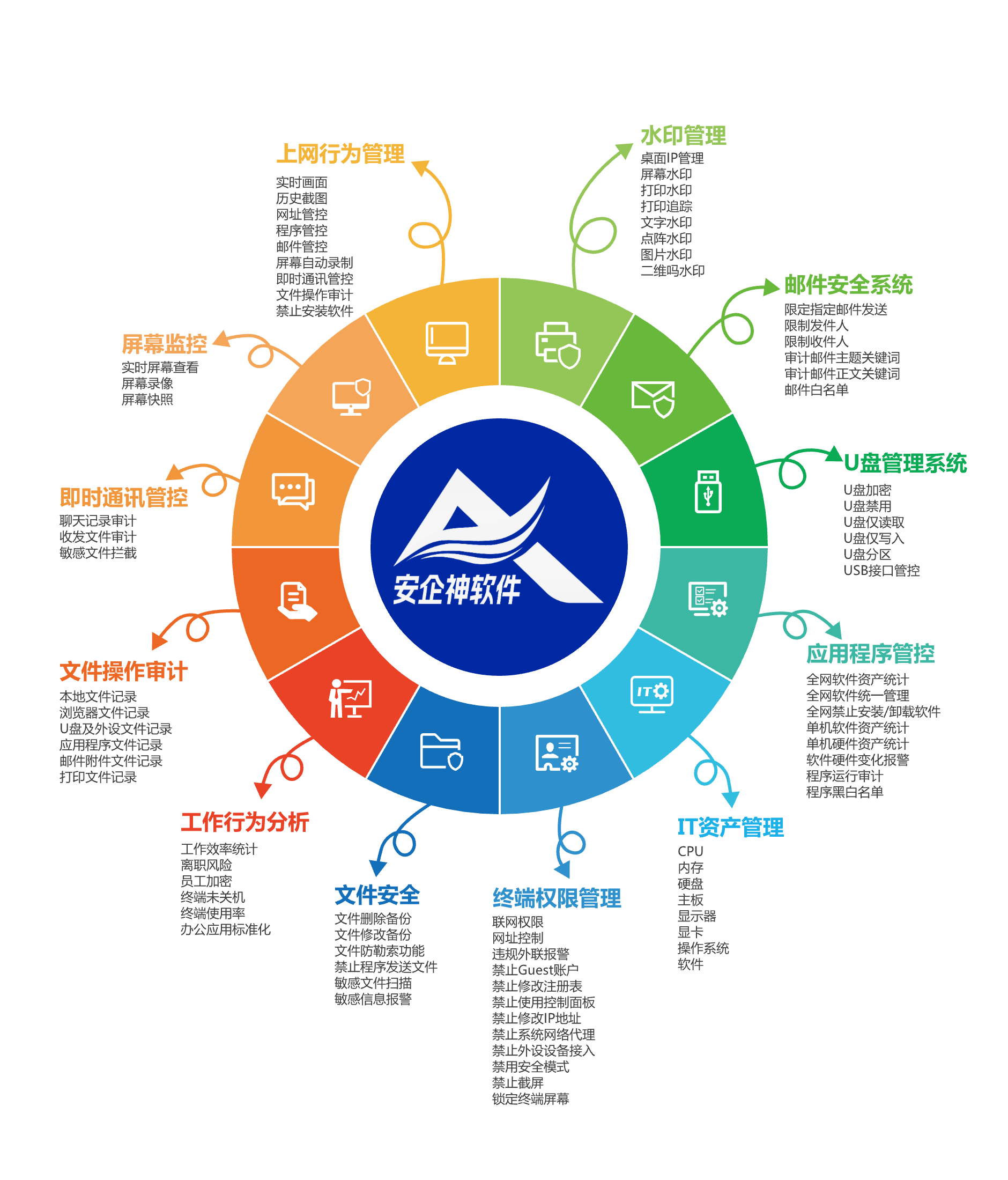
商业秘密泄露的方式有哪些?如何防止商业秘密泄露?五、安企神软件的防泄密优势安企神软件在防泄密方面具有以下优势:1、灵活多样的加密策略: 支持多种加密模式,满足企业不同场景下的加密需求2、全面的上网行为审计:。
实时监控员工的上网行为,防止员工泄露商业秘密3、强大的本地应用管控: 防止员工下载无关软件,保护电脑安全,防止数据泄露4、高效的远程运维管理: 实时了解员工的工作状态,提高管理效率,降低泄密风险

商业秘密泄露的方式有哪些?如何防止商业秘密泄露?六、安企神软件的应用场景安企神软件作为国内领先的数据安全厂商,推出了功能全面的数据安全解决方案,可以帮助企业有效保护数据安全,其应用场景非常广泛,包括:1、企业办公:
在企业办公环境中,员工经常会处理各种敏感数据,如合同、财务报表、设计图纸、客户信息等安企神软件可以帮助企业有效保护这些敏感数据,防止数据泄露2、医疗机构: 在医疗机构中,患者的病历、影像资料等信息属于高度敏感数据。
安企神软件可以帮助医疗机构保护患者隐私,防止医疗信息泄露3、政府机构: 在政府机构中,存储着大量的国家秘密和商业秘密安企神软件可以帮助政府机构保护这些敏感信息,防止国家秘密和商业秘密泄露4、科研机构: 在科研机构中,科研人员经常会进行一些机密的研究项目。
安企神软件可以帮助科研机构保护科研成果,防止科研成果泄露5、金融机构: 在金融机构中,存储着大量的客户信息和交易数据安企神软件可以帮助金融机构保护客户隐私和金融信息安全,防止金融信息泄露6、教育机构: 在教育机构中,存储着学生的学籍信息、考试成绩等数据。
安企神软件可以帮助教育机构保护学生隐私,防止学生信息泄露7、制造业: 在制造业中,企业拥有大量的技术图纸、生产工艺等知识产权信息安企神软件可以帮助制造企业保护知识产权,防止知识产权泄露总之,安企神软件是一款功能强大、易于管理的企业防泄密软件,能够有效防止商业秘密的泄露,保障企业的正常运营和市场竞争地位。
返回搜狐,查看更多责任编辑:
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。