7月19日下午2点,微软蓝屏把全球染上“科技蓝”“感谢微软,提前放假”的微博突然冲上热搜,打工人“提前下班”的背后,实际上是一家国外终端安全公司CrowdStrike软件更新,导致了Windows系统大面积蓝屏死机。
除了打工人们的电脑“提前下班”,此次微软Windows蓝屏事件也影响了人们的衣食住行,尤其欧美大量的机场、医院、媒体与银行由于Windows系统崩溃,陷入瘫痪状态,无数企业运营受阻堪称一场全球危机,马斯克也连连表示:“史上最大IT事故,没有之一”。
据美国研究机构安德森经济集团首席执行官帕特里克·安德森初步估算,此次微软技术故障事件造成的经济损失很可能超过10亿美元。机场蓝屏

超市蓝屏那么究竟是什么原因导致了如此严重的IT故障呢?CrowdStrike是一家全球知名的终端安全厂商,其核心产品Falcon是一款集中了企业端点安全、云安全、托管安全服务、安全和IT运营、威胁情报、身份保护和日志管理功能的云本地端点保护平台。
CrowdStrike目前的客户数超24000个,覆盖了大部分全球500强企业根据CrowdStrike官方故障说明,造成此次蓝屏事件的原因为其Falcon平台用于收集有关可能新型威胁技术数据的传感器(Sensor)。
传感器配置更新分为两种,Sensor Content 和 Rapid Response Content出问题的是Rapid Response Content 更新(用于迅速响应不断变化的威胁形势)7月19日,该更新通过Content Validator验证后,直接进行了发布。
更新触发的内存越界问题最终导致大面Wiindows系统蓝屏从北京时间12:09开始推送存在错误设定的更新,13:27停止推送该更新在此之后,已受到影响的Windows机器不会自动恢复,需要依赖手动恢复比如尝试CrowdStrike给出的官方方案进行手动操作:
1. 使用安全模式或恢复模式进入操作系统2. 进入C:\Windows\System32\drivers\CrowdStrike 目录3. 找到所有匹配“C-00000291*.sys”的文件,并将其删除
4. 正常启动主机或者直接重命名以下文件夹:“C:\Windows\system32\drivers\CrowdStrike这意味着一家企业如果有1000台电脑主机,上述操作需要手动操作1000次由于较高的手动恢复成本,7月25日故障发生后一周左右,根据CrowdStrike的评估,仍有3%受影响的windows系统尚未恢复。
同日,根据Health-ISAC 的首席安全官Errol Weiss表示,受到影响的健康保险行业的中,仅有18%的组织完全恢复许多企业办公场景和生产场景都会使用这样的第三方软件,由于安全问题和三方软件功能迭代,办公电脑和服务器需要不断地安装更新,诸如此类的事件也曾有发生。
2017年,三星的Tizen操作系统的一次更新导致部分智能电视和智能手表在更新后无法启动,变成“砖块”这一事件对用户带来了极大的不便,三星不得不发布修正补丁并提醒用户如何进行恢复2018年10月微软Windows 10的更新导致用户文件被删除。
一些用户报告说更新后他们的文档、照片和其他文件都消失了这一问题迫使微软紧急暂停了更新发布,并在后来推出了修复版本三方软件就像一个巨大的盲盒当发生这类问题时,由于对于三方软件缺乏技术上的深入了解,运维人员往往很难定位到是三方软件的问题,只能面对着蓝屏电脑、崩溃的服务器一头雾水。
那么,有没有可逆的操作来拯救不可控的危机风险,甚至未雨绸缪,防患未然呢?有几点思考和大家分享:首先,从产品设计角度,应当有节制地使用驱动方案什么是有节制的驱动方案?以安全产品举例,应当只有涉及到实时防御和拦截的功能才必须要基于驱动方案实现,其他所有的功能都是可以基于应用层设计的,这样可在设计阶段就保证不会将风险不断扩大。
根据现有信息以及CrowdStrike提供的解决方案,可以看到CrowdStrike的安全客户端在驱动模块上出现了问题从方案设计上看,就存在严重的稳定性隐患,核心问题在于CrowdStrike的核心驱动csagent.sys默认随系统启动加载,目前业界多款三方的安全客户端产品,也有类似的方案存在。
在驱动模块存在问题的情况下,最坏情况下将导致持续蓝屏和重启无法恢复的问题,就像本次发生的问题一样,CrowdStrike官方最终给的方案是进入安全模式或WinPE启动后删除出问题的sys驱动文件,也意味着随系统启动加载的驱动文件出现问题后,已经无法通过云端下发补丁的方式来管控了。
所以,我们认为在设计时应该是优先考虑应用层方案比如本次导致蓝屏的CrowdStrike的事件采集器,除了有驱动层方案外,也可以考虑通过应用层的方案实现,比如通过ETW的方式获取事件这样避免驱动的不稳定导致系统蓝屏的风险。
其次,从变更发布角度讲,总是要做最坏的打算,规划好灰度流程与回滚方案此次事件中,CrowdStrike推送的配置更新通过Content Validator验证后,直接进行了发布,为了迅速响应安全威胁牺牲了灰度。
云厂商在设计这类客户端产品时,一般会根据最小粒度即单机进行灰度,当然在机器规模非常大的时候,这种灰度方式会造成整体的变更周期很长以国内规模第一的阿里云为例,一般采用阶梯式的灰度发布,即逐个区域分批次发布,每批次发布机器数量范围逐步增加,最终达到一个相对平稳的发布数量批次完成全网发布,在发布时间和稳定性之间找到一个平衡。
此外,安全产品在进行风险比较高的防护操作前(比如操作系统漏洞修复,高危文件隔离等),可以结合云的原生能力,做一个系统快照备份一旦出现极端的意外情况,可以快速的通过快照回滚系统,进而保证业务快速恢复阿里云的云安全中心产品就提供类似的功能,客户可以选择“自动创建快照并修复漏洞”的模式,这样做好最坏的打算,最充分的准备。

(云安全中心漏洞修复提醒)最后,从企业应急恢复角度讲,虚拟化程度和自动化水平决定了定位和止血的效率如果是物理设备的底层操作系统崩溃,用户无法进行远程定位和止血,必须拿到存在问题的物理设备,有时IT人员与其距离较远,到达存在问题的物理设备会消耗大量时间,从而影响恢复效率。
云厂商具备的天然优势是,在虚拟机崩溃后,用户仍可直接远程使用系统运维管理服务,进行快速定位与止血例如用户被此类蓝屏事件影响,可通过ECS实例自助排查能力,快速定位三方软件问题,及时地定位问题根因对于一些已知的问题,知识库还应给出修复方案,解决企业因为缺乏专业排查工具而定位难的问题。

(ECS控制台自助问题排查)

(ECS实例问题排查定位的事件分析根因)同时在虚拟机崩溃后,用户仍可直接通过远程系统运维管理服务,如阿里云的OOS,可对受损机器进行批量操作,从而迅速止血,而无需先获取到存在问题的物理设备针对此次CrowdStrike造成的Windows 批量蓝屏事件,即使是拿到了解决方案,缺乏运维工具的企业需要一台一台地手动恢复。
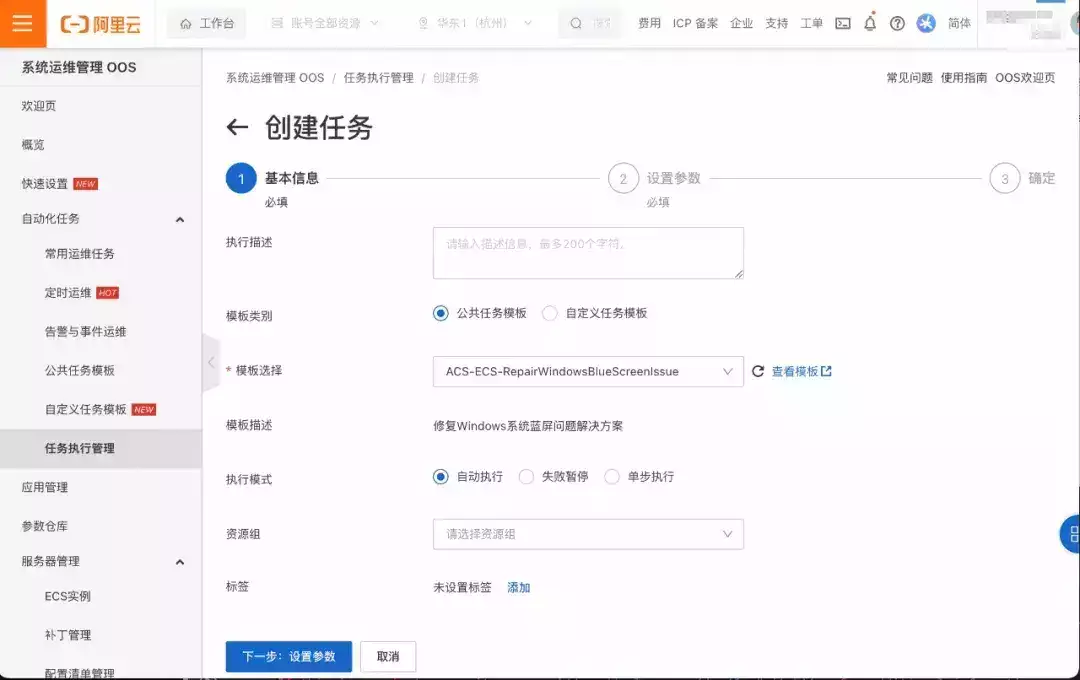
按照CrowdStrike 官网上提供的恢复方案,共四个步骤假设每个步骤平均操作需要20秒,有100台Windows 服务器或办公电脑的企业单人操作需要两个多小时相比之下,用户使用OOS只需要在执行模板(https://oos.console.aliyun.com/cn-hangzhou/execution/create/ACS-ECS-RepairWindowsBlueScreenIssue)时简单的选择要修复的ECS实例等参数,就可以一键对受损的实例进行批量修复。
整个自动化修复流程不仅大大减少了用户的修复时间,并且由于在模板中固化了修复流程,能够保证修复效果,避免手动修复过程中执行错误的情况写在最后总的来说,故障难以完全避免,而且基于终端的安全产品,在稳定性上有其天然的难度和挑战,随着终端的数量上升,稳定性挑战将呈几何级的上升。
特别是一款全球化大规模部署的终端产品,其面临的挑战更大,同时发生故障的影响将是极其严重的希望我们的分析讨论能够帮助客户业务和产品做的更健壮对于安全厂商来说,应当提升自身在设计、研发、变更上的控制能力,优先保障系统稳定,且厂商需要有对系统稳定地持续投入建设和优化,来降低故障风险。
对于产品用户来说,对于三方产品的引入和部署,应当有充分的调研和评估,避免引入不受控的风险;对于特别关键的系统,应该考虑在成本允许的条件下,在包括操作系统,基础设施等多个层面上进行“异构冗余”;对已上云的业务,通过利用好云平台提供的原生能力,能更好的在出现故障时进行规避和恢复,在一定程度上,能够帮助企业用户降低运维成本。
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。


发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。