在当今互联网时代,拥有一个网站只是第一步,如何让这个网站被搜索引擎收录并在搜索结果中获得较高排名,才是每个网站管理员需要重点关注的问题无论是企业网站、个人博客还是电商平台,都需要通过各种手段来提升自己在搜索引擎中的可见度。
下面,我们将从多个方面探讨如何提高网站的收录率一、优质内容是基础
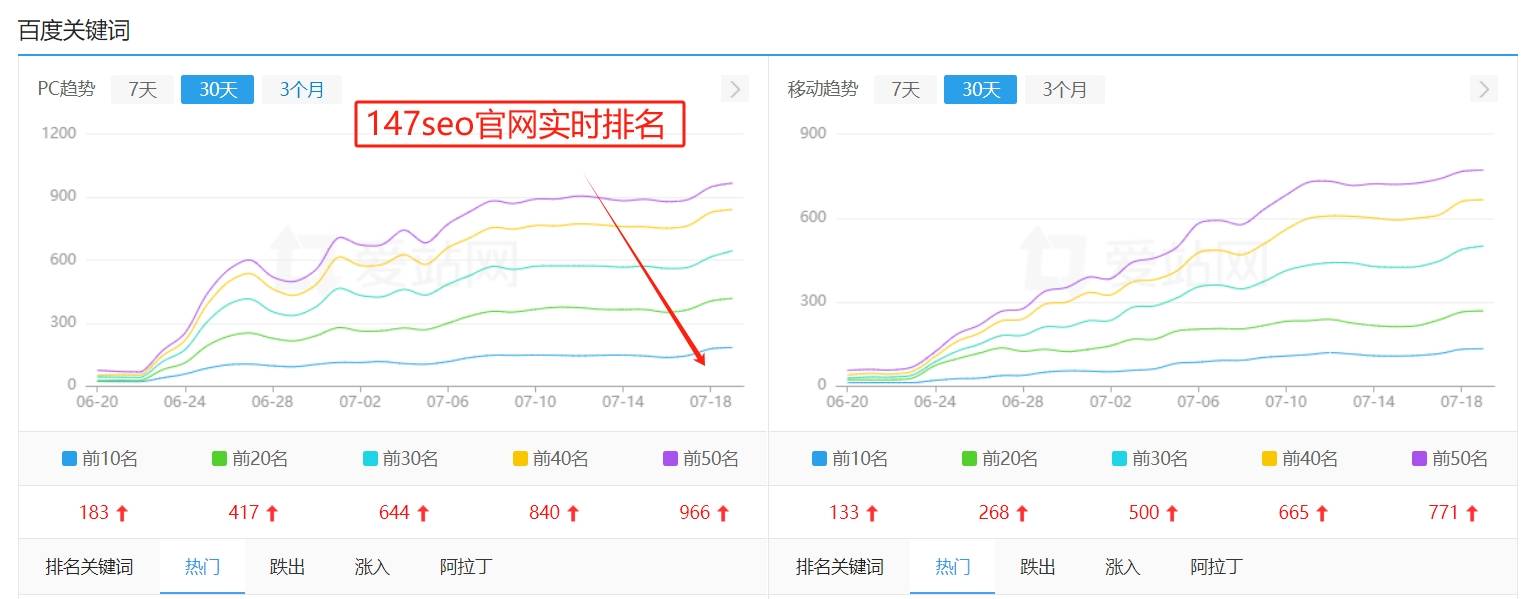
1.1原创内容搜索引擎对原创内容有着天然的偏好。重复的内容不仅难以吸引用户,对搜索引擎的友好度也会大打折扣。因此,网站应尽量发布原创、高质量的内容,以满足用户的需求并提高搜索引擎的收录意愿。
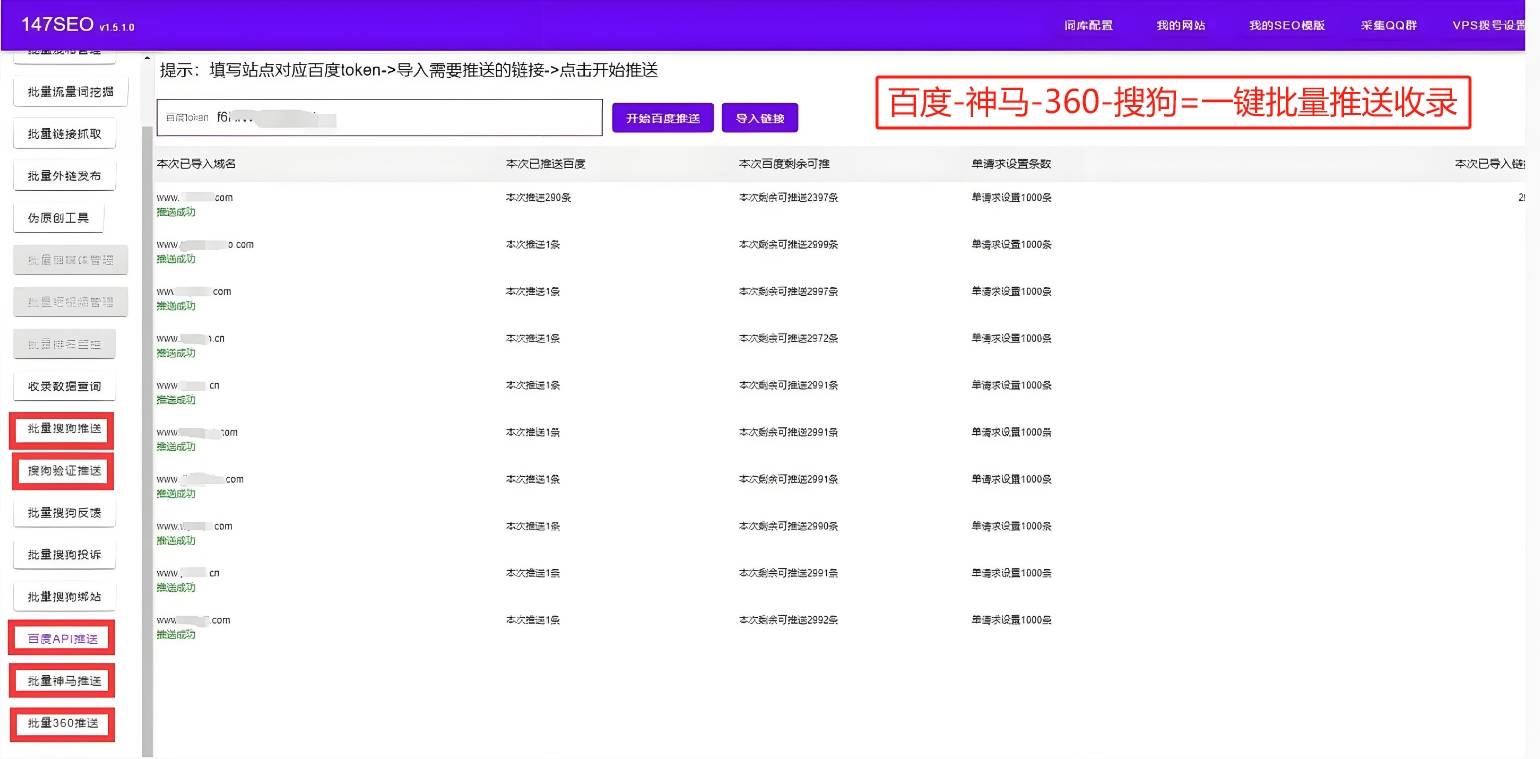
1.2定期更新内容的更新频率也是影响收录的重要因素。定期发布新内容,可以让搜索引擎频繁地访问和抓取你的网站,从而提高收录的机会。内容更新也有助于保持用户的活跃度和回访率。
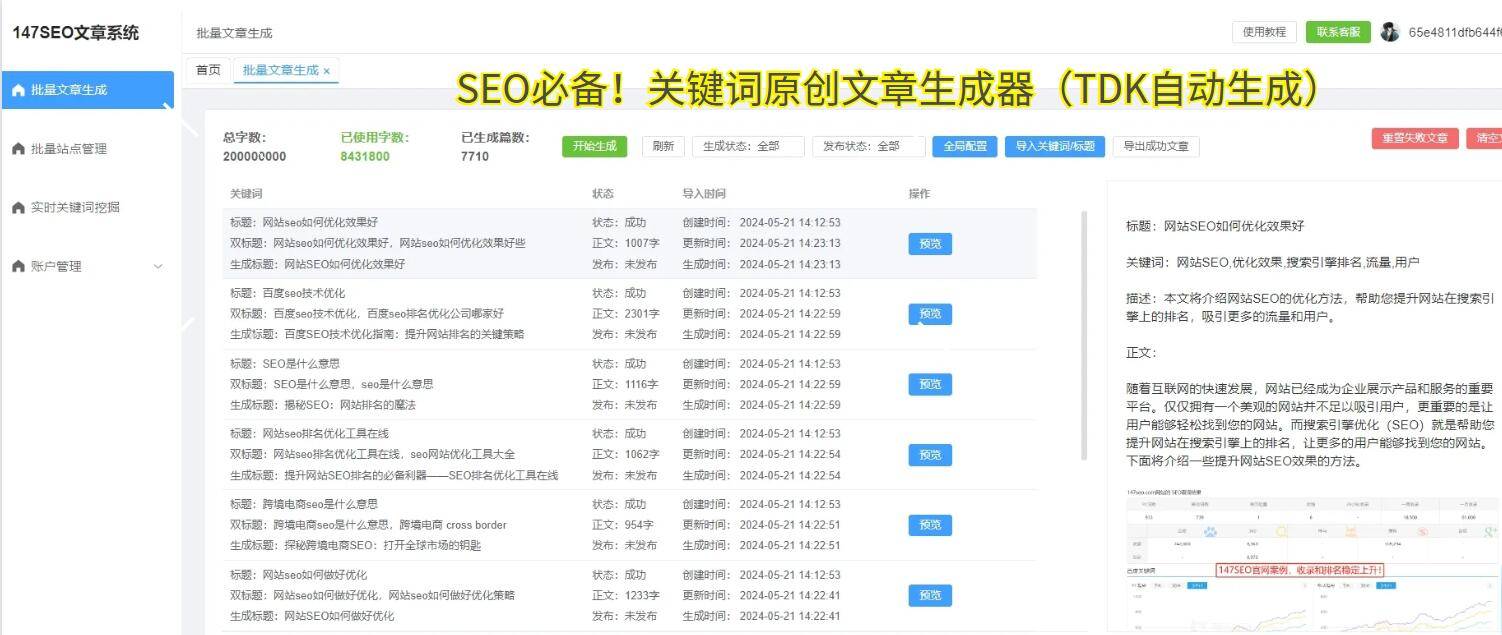
1.3关键词优化关键词是搜索引擎理解网页内容的重要依据合理使用关键词,可以提高网页在相关搜索中的排名需要注意的是,关键词的使用要自然流畅,避免过度堆砌,否则可能会被搜索引擎视为作弊行为二、技术优化不可忽视。
2.1网站结构清晰一个结构清晰、层次分明的网站,更容易被搜索引擎抓取网站的导航结构应简单明了,重要的内容应该尽量少层次嵌套,以便于搜索引擎蜘蛛爬行和索引2.2响应式设计随着移动设备的普及,越来越多的用户通过手机或平板访问网站。
确保网站具有良好的移动端体验,可以提升搜索引擎对网站的评价目前,许多搜索引擎已经开始将移动端适配性作为重要的排名因素之一2.3网站速度优化网站加载速度不仅影响用户体验,也是搜索引擎排名的重要指标通过优化图片大小、减少页面重定向、使用CDN等手段,可以显著提升网站的加载速度,从而提高搜索引擎的收录率。
2.4SSL证书安装SSL证书,使网站支持HTTPS访问,可以提高搜索引擎对网站的信任度自2014年以来,谷歌就将HTTPS作为排名信号之一因此,确保网站使用HTTPS,有助于提升在搜索结果中的排名三、外部链接与社交媒体
3.1高质量的外部链接外部链接,尤其是来自高权重网站的链接,可以显著提高网站的权威性和可信度寻找行业内的高质量网站进行合作交换链接,或通过发布优质内容吸引其他网站主动链接,是提升搜索引擎收录的重要手段3.2社交媒体互动
活跃的社交媒体活动,可以为网站带来大量的访问流量,同时也有助于搜索引擎更快地发现和收录新内容通过在社交媒体上分享网站内容,增加用户互动,有助于提高网站的曝光度和权重四、网站地图与提交4.1创建网站地图网站地图是一个列出网站所有页面的文件,可以帮助搜索引擎更好地了解和抓取你的网站内容。
创建并提交网站地图,可以显著提高搜索引擎的收录效率4.2主动提交网址在网站上线或更新重要内容后,可以主动向搜索引擎提交网址通过搜索引擎的站长工具,可以手动提交网站的新页面,确保搜索引擎能够及时发现和收录这些内容。
五、用户体验与反馈5.1优化用户体验良好的用户体验,不仅能够提高用户的停留时间和回访率,还能间接影响搜索引擎的收录和排名确保网站界面友好,导航清晰,内容易读,是提升用户体验的关键5.2收集用户反馈通过用户反馈,可以及时发现并解决网站存在的问题,进一步优化网站的内容和功能。
这不仅有助于提高用户满意度,也能提升搜索引擎对网站的评价结论网站收录是一个复杂的过程,涉及内容、技术、外部链接、社交媒体、用户体验等多个方面通过系统地优化这些方面,可以显著提高网站的收录率和搜索引擎排名。
在激烈的互联网竞争中,只有不断提升网站的质量和可见度,才能获得更多的用户和流量希望本文提供的建议,能够帮助你的网站在搜索引擎中脱颖而出,获得更好的发展返回搜狐,查看更多责任编辑:
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。