IT之家 8 月 21 日消息,科技媒体 bleepingcomputer 昨日(8 月 20 日)报道,有黑客利用近期修复的 PHP 远程代码执行漏洞(CVE-2024-4577),在 Windows 系统上部署名为“Msupedge”的后门
CVE-2024-4577IT之家曾于今年 6 月、7 月报道,PHP for Windows 安装包中存在远程代码执行(RCE)漏洞,影响到自 5.x 版以来的所有版本,可能对全球大量服务器造成影响官方已经于 6 月发布补丁修复了该漏洞,未经认证的攻击者利用该漏洞可以执行任意代码,并在成功利用后可以让系统完全崩溃。
Msupedge 后门攻击者制作并投放了 weblog.dll(Apache 进程 httpd.exe 装载)和 wmiclnt.dll 两个动态链接库文件,使用 DNS 流量与命令与控制(C&C)服务器进行通信。
该漏洞利用 DNS 隧道(基于开源 dnscat2 工具实现的功能),在 DNS 查询和响应中封装数据,以接收来自其 C&C 服务器的命令。
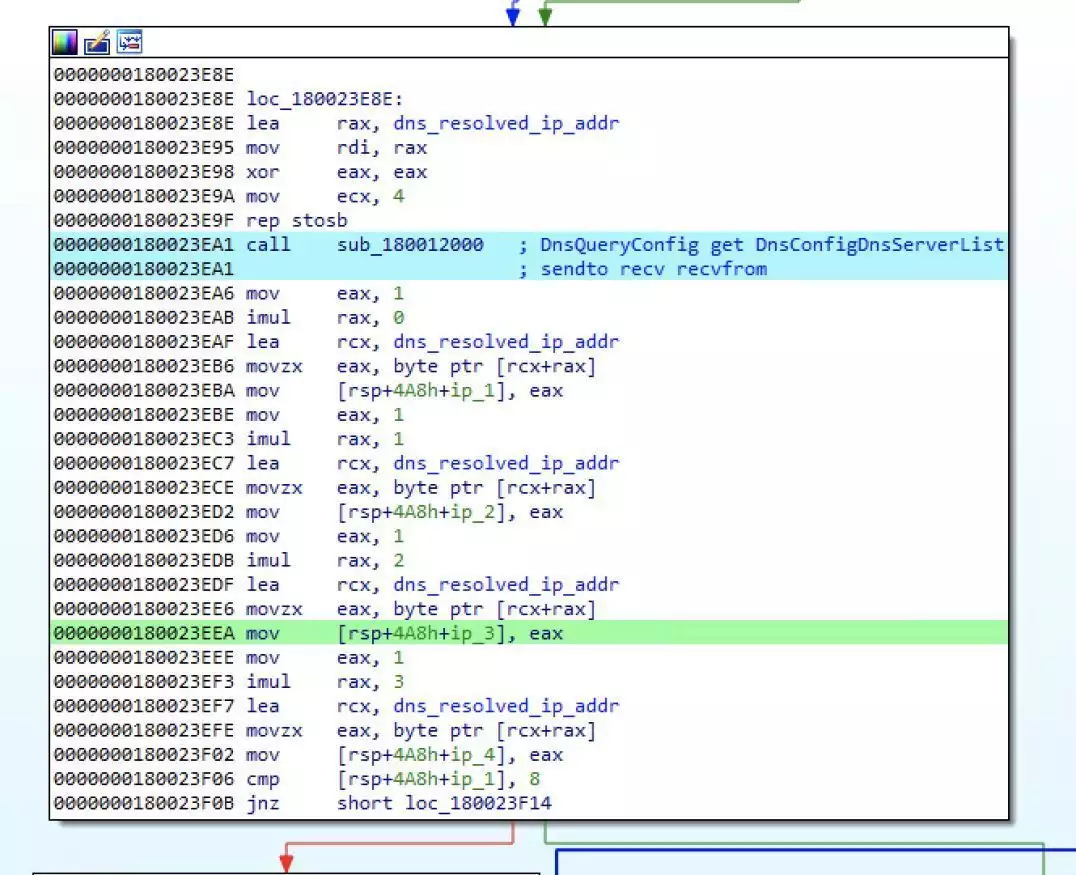
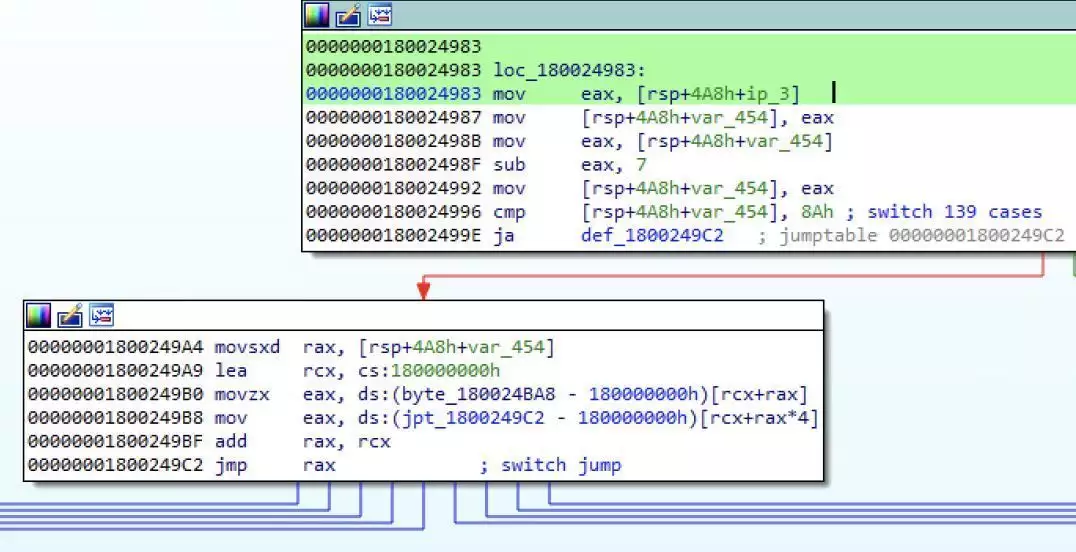
攻击者可以利用 Msupedge 执行各种命令,这些命令是根据 C&C 服务器解析 IP 地址的八比特(Octet)第三位触发的该后门还支持多种命令,包括创建进程、下载文件和管理临时文件赛门铁克 Threat Hunter Team 团队深入调查了该漏洞,认为攻击者是利用 CVE-2024-4577 漏洞入侵系统的。
该安全漏洞绕过了 PHP 团队针对 CVE-2012-1823 实施的保护措施,而 CVE-2012-1823 在修复多年后被恶意软件攻击利用,利用 RubyMiner 恶意软件攻击 Linux 和 Windows 服务器。

亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。