基础知识(1)什么是同步IO和异步IO,它们之间有什么区别?答:举个现实例子,假设你需要打开4个不同的网站,但每个网站都比较卡IO过程就相当于你打开网站的过程,CPU就是你的点击动作你的点击动作很快,但是网站打开很慢。
同步IO是指你每点击一个网址,都等待该网站彻底显示,才会去点击下一个网址异步IO是指你点击完一个网址,不等对方服务器返回结果,立马新开浏览器窗口去打开另外一个网址,以此类推,最后同时等待4个网站彻底打开。
很明显异步IO的效率更高(2)什么是协程,为什么要使用协程?Python中解决IO密集型任务(打开多个网站)的方式有很多种,比如多进程、多线程但理论上一台电脑中的线程数、进程数是有限的,而且进程、线程之间的切换也比较浪费时间。
所以就出现了“协程”的概念协程允许一个执行过程A中断,然后转到执行过程B,在适当的时候再一次转回来,有点类似于多线程但协程有以下2个优势:协程的数量理论上可以是无限个,而且没有线程之间的切换动作,执行效率比线程高。
协程不需要“锁”机制,即不需要lock和release过程,因为所有的协程都在一个线程中相对于线程,协程更容易调试debug,因为所有的代码是顺序执行的Python中的异步IO和协程Python中的协程是通过“生成器(generator)”的概念实现的。
这里引用廖雪峰Python教程中的例子,并做一点修改和“装饰”:defconsumer():# 定义消费者,由于有yeild关键词,此消费者为一个生成器print("[Consumer] Init Consumer ......"
)r="init ok"# 初始化返回结果,并在启动消费者时,返回给生产者whileTrue:n=yieldr# 消费者通过yield接收生产者的消息,同时返给其结果print("[Consumer] conusme n =
%s, r = %s"%(n,r))r="consume %s OK"%n# 消费者消费结果,下个循环返回给生产者defproduce(c):# 定义生产者,此时的 c 为一个生成器print("[Producer] Init Producer ......"
)r=c.send(None)# 启动消费者生成器,同时第一次接收返回结果print("[Producer] Start Consumer, return %s"%r)n=0whilen<5:n+=1print
("[Producer] While, Producing %s ......"%n)r=c.send(n)# 向消费者发送消息并准备接收结果此时会切换到消费者执行print("[Producer] Consumer return: 。
%s"%r)c.close()# 关闭消费者生成器print("[Producer] Close Producer ......")produce(consumer())代码中添加了很详细的print语句和注释,帮助大家更好的理解。
这里删除了源代码consumer中的“return”语句如果还是不太明白,可以在编辑器中进行debug调试,一步步跟踪程序的运行过程关于异步IO,在Python3.4中可以使用asyncio标准库该标准库支持一个时间循环模型(EventLoop),我们声明协程,然后将其加入到EventLoop中,即可实现异步IO。
Python中也有一个关于异步IO的很经典的HelloWorld程序(同样参考于廖雪峰教程):# 异步IO例子:适配Python3.4,使用asyncio库@asyncio.coroutinedefhello
(index):# 通过装饰器asyncio.coroutine定义协程print(Hello world! index=%s, thread=%s%(index,threading.currentThread
()))yieldfromasyncio.sleep(1)# 模拟IO任务print(Hello again! index=%s, thread=%s%(index,threading.currentThread
()))loop=asyncio.get_event_loop()# 得到一个事件循环模型tasks=[hello(1),hello(2)]# 初始化任务列表loop.run_until_complete
(asyncio.wait(tasks))# 执行任务loop.close()# 关闭事件循环列表同样这里的代码添加了注释,并增加了index参数输出currentThread的目的是演示当前程序都是在一个线程中执行的。
返回结果如下:Hello world! index=1, thread= Hello world! index=2, thread= Hello again! index=1, thread= Hello again! index=2, thread=
在Python3.5中引入了关于异步IO的新语法:async和await关键字# 异步IO例子:适配Python3.5,使用async和await关键字asyncdefhello(index):# 通过关键字async定义协程。
print(Hello world! index=%s, thread=%s%(index,threading.currentThread()))awaitasyncio.sleep(1)# 模拟IO任务
print(Hello again! index=%s, thread=%s%(index,threading.currentThread()))loop=asyncio.get_event_loop()
# 得到一个事件循环模型tasks=[hello(1),hello(2)]# 初始化任务列表loop.run_until_complete(asyncio.wait(tasks))# 执行任务loop.
close()# 关闭事件循环列表从代码中可以看出,使用async代替@asyncio.coroutine,使用await代替yield from,使得协程代码更加简洁易懂async关键字将一个函数声明为协程函数,函数执行时返回一个协程对象。
await关键字将暂停协程函数的执行,等待异步IO返回结果。这里还出现了一个新词:事件循环模型EventLoop,这又是个什么呢?
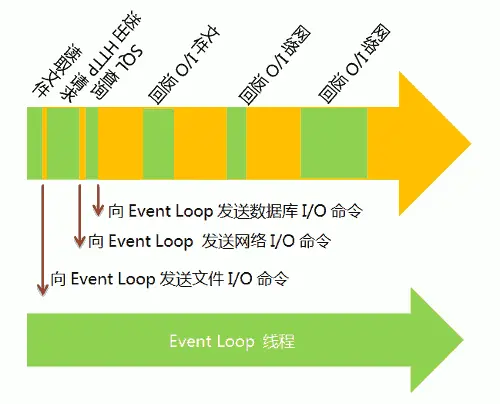
EventLoop是一个程序结构,用于等待和发送消息和事件简单说,就是在程序中设置两个线程:一个负责程序本身的运行,称为"主线程";另一个负责主线程与其他进程(主要是各种I/O操作)的通信,被称为"Event Loop线程"(可以译为"消息线程")。
在爬虫中使用协程实现异步IO异步IO特别适合爬虫的工作,因为爬虫中所有的请求都属于IO密集型任务,想得到比较好的爬虫效率,使用协程很重要关于Http异步请求,建议使用aiohttp库,一个异步的HTTP客户端/服务器框架。
这里举个例子,更多用法可以参考其官方文档asyncdefget(url):asyncwithaiohttp.ClientSession()assession:asyncwithsession.get(url
)asresp:print(url,resp.status)print(url,awaitresp.text())loop=asyncio.get_event_loop()# 得到一个事件循环模型tasks
=[# 初始化任务列表get("http://zhushou.360.cn/detail/index/soft_id/3283370"),get("http://zhushou.360.cn/detail/index/soft_id/3264775"
),get("http://zhushou.360.cn/detail/index/soft_id/705490")]loop.run_until_complete(asyncio.wait(tasks
))# 执行任务loop.close()# 关闭事件循环列表老规矩,以上所有代码均上传至Github:https://github.com/xianhu/LearnPython另外关于aiohttp库的使用,我也会整理一份代码,上传到GitHub。
=============================================================作者主页:笑虎(Python爱好者,关注爬虫、数据分析、数据挖掘、数据可视化等)
作者专栏主页:撸代码,学知识 - 知乎专栏作者GitHub主页:撸代码,学知识 - GitHub欢迎大家拍砖、提意见相互交流,共同进步!==============================================================。
发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。