
点击“各类办公软件学习”快速关注

Word表格转成excel表格Excel和Word都是常用的办公软件,利用Word、Excel都可以编制表格,今日分享如何将Word表格转成Excel表格01打开Word文档,进入Word的操作界面,如图所示:。

02按下Ctrl+O键,在弹出的对话框内找到word表格文件,如图所示:
03打开Word表格文件之后,在菜单里找到文件选项,如图所示:
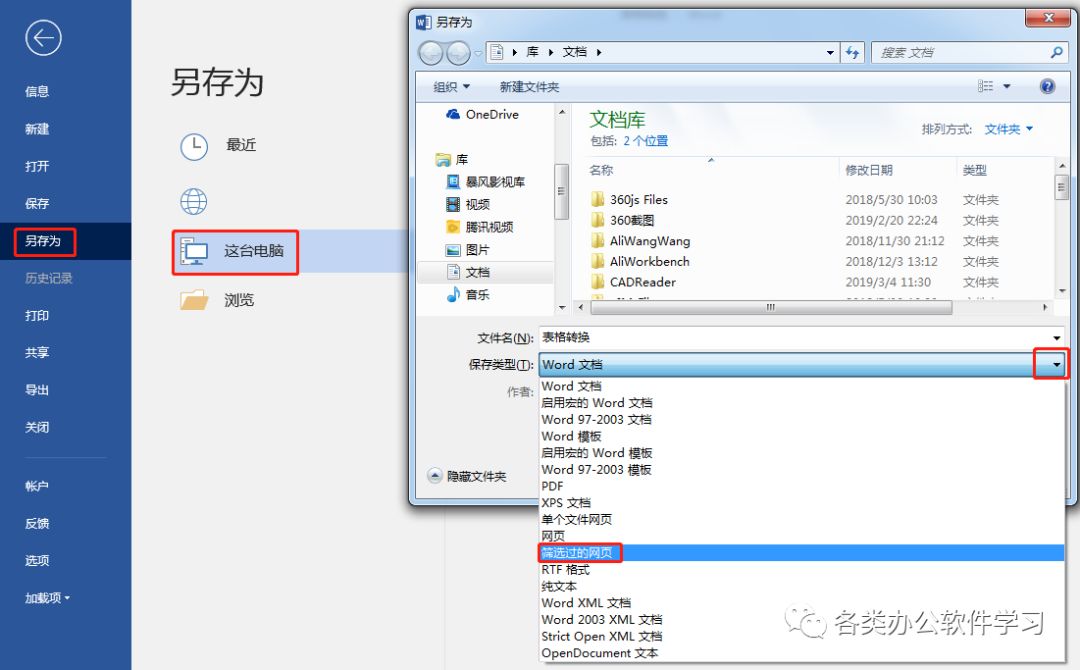
04点击文件选项,在其下拉菜单里找到另存为选项,如图所示:
05点击另存为选项,选择这台电脑,在弹出的对话框内找到保存类型选项,将保存类型设置为网页,如图所示:
06设置好以后点击保存,关掉Word文档,打开Excel文档,在打开的Excel界面内找到文件选项,如图所示:
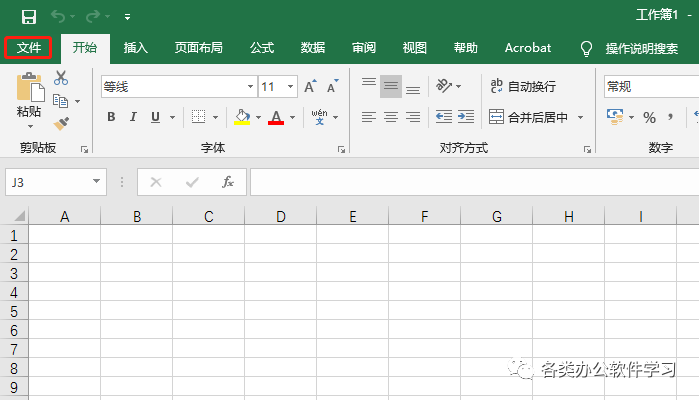
07点击文件菜单,在其下拉菜单里找到打开选项,选择最近,在弹出的对话框内找到刚导出的Word网页文档,如图所示:

08选择网页文件点击打开,就可以将Word表格导入到Excel内,如图所示:
每个人都有一个死角,自己走不出来,别人也闯不进去;每个人都有一道伤口或深或浅,盖上布,以为不存在学习也一样,自己不想学,别人怎么教也教不会我们总是看不见自己的不足,却只想选择安于现状长按识别关注微课office学习平台。
PowerPoint | Excel | Word | 课程同步长按识别添加微信客服
感谢您抽出

.
.
来阅读本文请右键单击下方数据透视表并选择“显示字段列表”)。一言不合就给我在看
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。