教程领到手,学习不用愁!领其实做Excel的表格并不难,但是大神仅仅花几分钟,就能完成你花几小时甚至更长的时间才能完成的工作,你是不是很生气呢?哈哈,没事下面这套知识兔教程将助你成为大神:

知识兔,让你不再因为Excel问题而加班如果你有Excel问题不能解决可以私聊我,公众号“超乎想象”将尽心替你解决,授人以鱼不如知识兔授人以渔其实想要完成这个并不难,下面我就来分享几个Excel实用的巧技能,大家可以先学起来。
慢慢迈入大神的门槛一、批量处理行高、列宽点击行标或列标,选中需要统一行或者列区域,将鼠标放在行标或列标之间的线上,待鼠标变化为黑色带双向箭头时候拖拽行标或列标之间的线。
二、快速填充数值在第一行单元格中手动输入身份证号中的出生日期,鼠标移动到本单元格右下角待鼠标变成黑色十字架后双击一下,点击最下面的“自动填充选项”,选择“快速填充”
三、批量在数字前加汉字选中数字单元格区域,按键盘上的Ctrl+数字1打开单元格格式窗口,选择数字-自定义,在类型中输入代码:“编号:”00(注意,必须使用英文状态下的引号)
四、查找重复值选取查找数据的区域,点击开始-条件格式-突出显示单元格规则-重复值,选择重复-浅红色填充重复的单元格
五、快速移动选取数据选择需要移动的数据区域,鼠标移动到选取边框线上,使鼠标箭头变为黑色实心状态,按住shift键并点击鼠标左键拖拽,拖到正确位置后先松开鼠标,然后在放开shift键
六、多个工作表同时输入内容首先利用Ctrl键选中多个工作表,然后直接输入内容,之后回车,并且取消组合工作表即可。
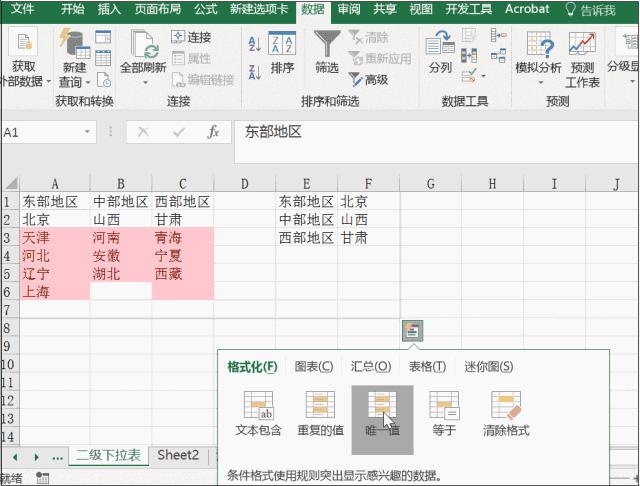
七、快速标示唯一值和重复值想要标识唯一值和重复值除了利用条件格式实现之外,利用快速分析也是一种非常实用的技巧,直接选中区域,右击选择快速分析下的唯一值或重复值即可。



亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。