公司新来的小姐姐,超级喜欢看漫画,天天给我介绍,好烦~现在是2022年9月15日16点30,于是我决定, 五点下班前写个代码把她说的漫画全部爬下来,应付一下~再发篇文章揭露她的罪恶,嘿嘿~
准备事项环境使用Python 3.8Pycharm 2021.2版本模块使用import requests >>> # 数据请求模块 pip install requestsimport re # 正则模块
import os # 文件操作模块基本流程思路一. 数据来源分析1. 确定自己需求: 采集那个网站上面什么数据内容 dongmanmanhua 网址自己补全一下,实在不知道的话文末见。
正常访问流程: 1. 选中漫画 ---> 目录页面 2. 选择一个漫画内容 ---> 漫画页面 3. 看漫画内容
分析流程: 1. 查看漫画图片url地址, 是什么样子 https://cdn.聪明的人看到这里已经补全了.cn/166052717362315191169.jpg?x-oss-process=image/quality,q_90
2. 分析url地址在哪里 通过搜索功能 166052717362315191169 https://www.*****.cn/BOY/moutianchengweimoshen/116-%E7%AC%AC43%E7%AB%A0-%E5%A2%9E%E5%8A%A0%E6%88%98%E6%96%97%E5%8A%9B%E5%90%A73/viewer?title_no=1519&episode_no=116
F12打开开发者工具, 进行刷新网页点击Img通过对比分析请求url地址变化 —> 漫画内容都是来于章节链接里面二. 代码实现步骤过程1. 发送请求 ---> 对于目录页面发送请求2. 获取数据 ---> 服务器返回响应数据
3. 解析数据 ---> 提取想要章节链接 / 漫画名字 / 章节名字4. 发送请求 ---> 对于章节链接发送请求5. 获取数据 ---> 服务器返回响应数据 6. 解析数据 ---> 提取想要图片链接
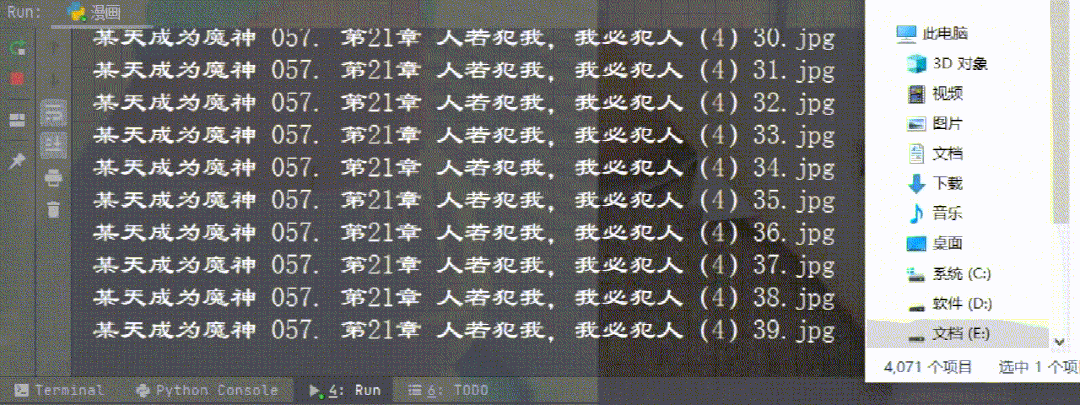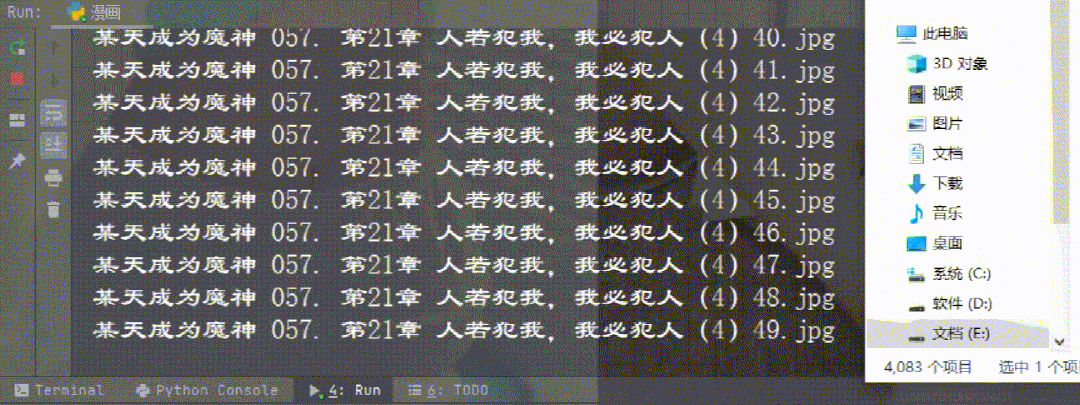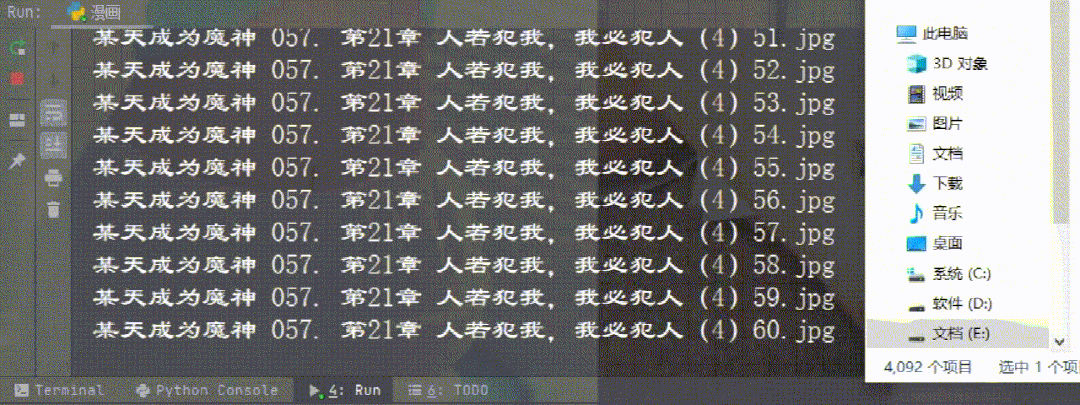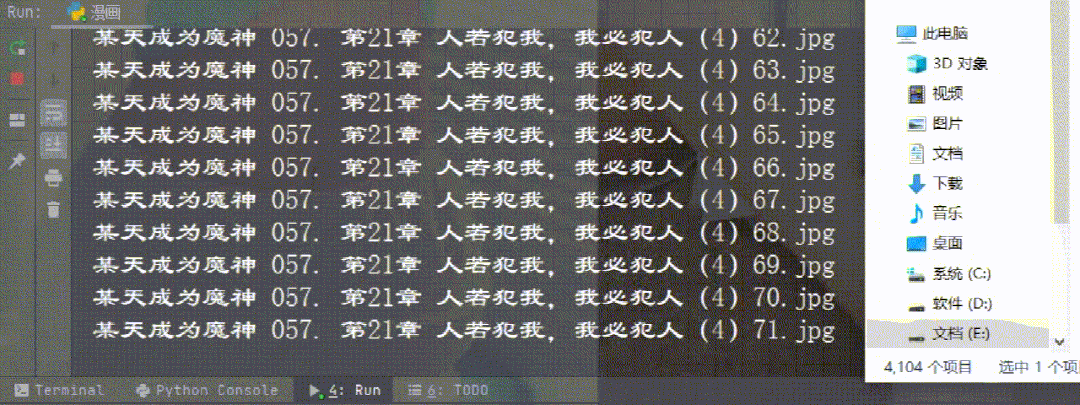
7. 保存数据 ---> 保存到本地效果展示不知不觉都四千多张图了,大家别一窝蜂去爬了,等下网站崩了就不好了~
代码展示发送请求def 自定义函数关键字get_response: 自定义函数名字模拟浏览器对于url地址发送请求param html_url: 自定义形式参数return: 响应对象defget_response
(html_url):# 请求头 headers 模拟浏览器 ---> 字典数据类型, 构建完整键值对 headers = {# referer 防盗链 告诉服务器请求url地址 是从哪里跳转过来
referer: https://www.dongmanmanhua.cn/,# User-Agent 浏览器基本身份信息User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36
}# 通过数据请求模块 去发送请求 response = requests.get(url=html_url, headers=headers)# return 返回 ---> 在代码里面 调用 get_response 函数 这个函数, 会给我们返回 response 这个数据
return response获取章节链接 / 漫画名字 / 章节名字defget_info(html_url):# 调用发送请求函数 html_data = get_response(html_url).text
# re正则提取数据 name = re.findall("title_title: (.*?),", html_data)[0] # 提取漫画名字 chapter_url_list = re.findall(
data-sc-name="PC_detail-page_related-title-list-item".*?href="(.*?)", html_data, re.S) title_list = re.findall(
(.*?), html_data)return name, chapter_url_list, title_list获取漫画url地址
defget_img_url(chapter_url):# 调用发送请求函数 chapter_data = get_response(chapter_url).text# re获取所有漫画图片内容
img_url_list = re.findall(alt="image" class="_images _centerImg" data-url="(.*?)", chapter_data)# 403 Forbidden 没有访问权限 ---> 通过代码得到数据 请求头里面加防盗链
return img_url_list保存数据defsave(name, title, img_url):""" :param name: 漫画名 :param title: 图片名 :param img_url: 图片链接
:return: """# 自动创建文件夹 file = fimg\\{name}\\# 如果没有这个文件夹的话ifnot os.path.exists(file):# 自动创建文件夹
os.makedirs(file)# 对于图片链接发送请求 获取二进制数据 img_content = get_response(img_url).content# file + title 保存地方以及保存文件名 mode 保存方式
with open(file + title, mode=wb) as f:# 写入数据 f.write(img_content) print(name, title)主函数整合上面所有内容
defmain(page):# 目录页面 link = fhttps://地址我删了,会被屏蔽.cn/BOY/moutianchengweimoshen/list?title_no=1519&page=
{page}# 调用获取章节链接 / 漫画名字 / 章节名字 函数 name, chapter_url_list, title_list = get_info(link)# for循环遍历 提取数据
for chapter_url, chapter_title in zip(chapter_url_list, title_list):# 字符串拼接 chapter_url = https:
+ chapter_url# 获取漫画内容 img_url_list = get_img_url(chapter_url)# for循环遍历 提取数据 num = 1for
img_url in img_url_list: title = chapter_title + str(num) + .jpg# 调用保存数据函数 save(name, title, img_url)
# 每次循环 +1 num += 1函数入口, 当你代码被当作模块调用的时候, 下面的代码不执行if __name__ == __main__:for page in range(。
12, 0, -1): main(page)好了,今天的分享就到这喽,完整源码及视频讲解在这个群 279199867 自取即可~最后分享一套Python教程:https://www.bilibili.com/video/BV1SA4y1976A
希望对你有所帮助哈~
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。





发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。