作者:闰土吃瓜大家好我是闰土吃瓜专注于支付优惠以及各种优惠活动喜欢我文章的记得关注点赞以及收藏任性的大佬可以打赏文章下!感激不尽!好了,咱们言归正传!往下看前言来了,闰土来了!今天给大家分享的是支付宝两个拿消费红包活动!直接免费领取就好了!。
活动1支付宝金秋消费节每天免费拿红包活动路径:点击下方直达界面进入活动界面后,点击抢红包,一直点到了当天次数完了,每天大概能有个几块钱不等,每天还能集齐活动界面下方亚运加油4个字,每天瓜分红包!
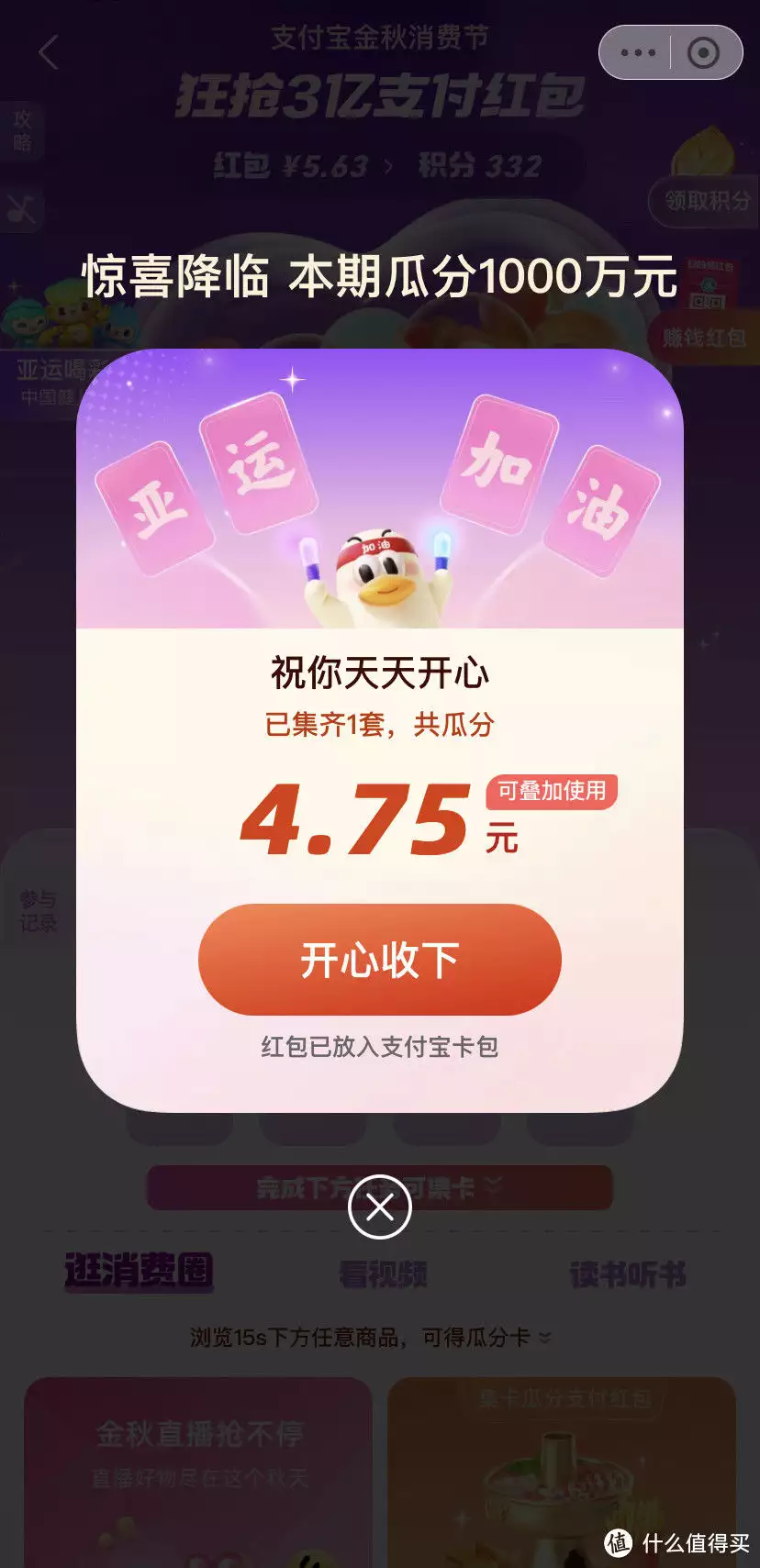
PS:特别是每天的集卡红包,必须要参加,每天浏览几个任务随便就可以集齐4个字,每天瓜分个几块十几块很正常,这个活动时间截止到2023年10月8日!
广告胆小者勿入!五四三二一...恐怖的躲猫猫游戏现在开始!×闰土亲测,这几天每天都去拿红包啥的,今天大概领取了9块多,其中还有个7.6元大包呢!
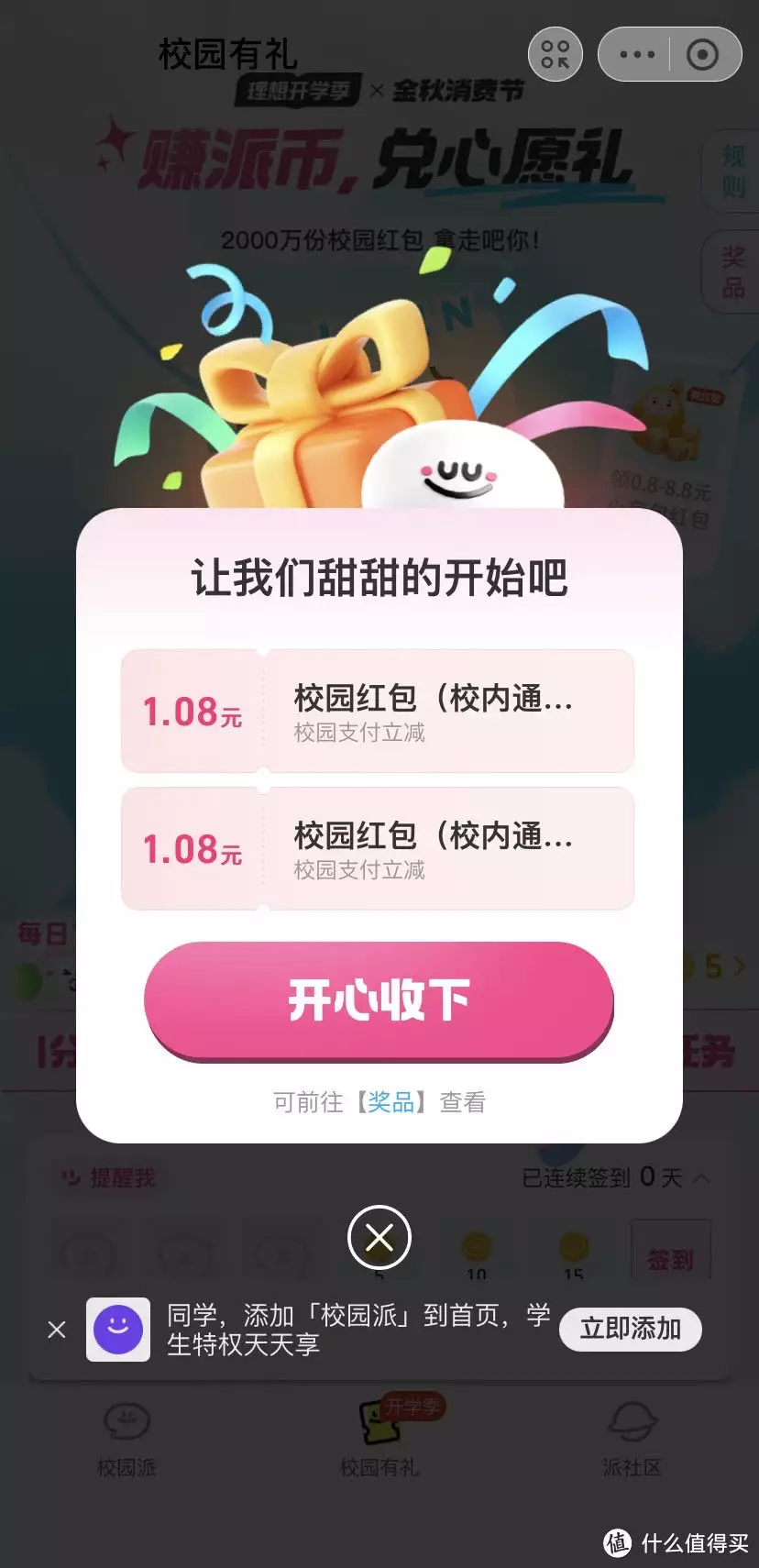
活动2校园派免费领取5个1.08元消费红包活动路径:点击下方直达界面进入活动界面后,可直接领取5个1.08元红包PS:这5个消费红包,限于在校大学生使用,在学校的食堂/智能设备/等其他支付工具,都可以用!
广告从秘书起步,十年内无人超越,以一己之力力挽狂澜成就一段传奇×好了,这篇文章就写到这里了,我是闰土吃瓜关注我或点我头像进去可以看到我各种支付优惠或优惠活动的原创文章,优惠攻略!有任何问题欢迎在评论区留言,闰土会一一回复,我们下期再会!
阅读更多支付精彩内容,可前往什么值得买查看
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。