php零基础入门视频课程
前排福利

关注公众号后台回复:181121,181122,181123,181126,181127,181128,181129,181101,181102,181103,1811PHP06,181107,181108,
181109等关键字,即可免费获取网页制作特效源码。回复【菜单源码】,【淘宝分类导航】,【画像】免费获取特效源码回复【电子书】免费获取python学习教程回复【网页特PHP效】免费获取更多内容哦~
码农那点事儿关注我们,一起学习进步

作者丨titanjfwww.cnblogs.com/titanjf/p/python-web-deploy.html

不要让服务器裸奔学过PHPPHP的都了解,php的正式环境部署非常简单,改几个文件就OK,用FastCgi方式也是分分钟的事情相比起来,Python在web应用上的部署就繁杂的多,主要是工具繁多,主流服务器支持不足,在了解PythoPHPn的生产环境部署方式之前,先明确一些概念!很重要!。
CGI:CGI即通用网关接口(Common Gateway Interface),是外部应用程序(CGI程序)与Web服务器之间的接口标准,是在CGPHPI程序和Web服务器之间传递信息的规程CGI规范允许Web服务器执行外部程序,并将它们的输出发送给Web浏览器,CGI将Web的一组简单的静态超媒体文档变成一个完整的新的交互式媒体。
通俗的讲CGI就像PHP是一座桥,把网页和WEB服务器中的执行程序连接起来,它把HTML接收的指令传递给服务器的执行程序,再把服务器执行程序的结果返还给HTML页CGI 的跨平台性能极佳,几乎可以在任何操作系统上实现。
CGIPHP方式在遇到连接请求(用户请求)先要创建cgi的子进程,激活一个CGI进程,然后处理请求,处理完后结束这个子进程这就是fork-and-execute模式所以用cgi方式的服务器有多少连接请求就会有多少PHPcgi子进程,子进程反复加载是cgi性能低下的主要原因。
当用户请求数量非常多时,会大量挤占系统的资源如内存,CPU时间等,造成效能低下
CGI脚本工作流程:浏览器通过HTML表单或超链接请求指向一个CGPHPI应用程序的URL服务器执行务器收发到请求所指定的CGI应用程序CGI应用程序执行所需要的操作,通常是基于浏览者输入的内容CGI应用程序把结果格式化为网络服务器和浏览器能够理解的文档(通常是HTML网PHP页)。
网络服务器把结果返回到浏览器中。python有cgi模块可支持原生cgi程序
FastCGI:FastCGI是一个可伸缩地、高速地在HTTP server和动态脚本语言间通信的接口多数流行的HTTPHPP server都支持FastCGI,包括Apache、Nginx和lighttpd等,同时,FastCGI也被许多脚本语言所支持,其中就有Python。
FastCGI是从CGI发展改进而来的传统CGPHPI接口方式的主要缺点是性能很差,因为每次HTTP服务器遇到动态程序时都需要重新启动脚本解析器来执行解析,然后结果被返回给HTTP服务器这在处理高并发访问时,几乎是不可用的。
FastCGI像是一个常驻(PHPlong-live)型的CGI,它可以一直执行着,只要激活后,不会每次都要花费时间去fork一次(这是CGI最为人诟病的fork-and-execute 模式)CGI 就是所谓的短生存期应用程序,FaPHPstCGI 就是所谓的长生存期应用程序。
由于 FastCGI 程序并不需要不断的产生新进程,可以大大降低服务器的压力并且产生较高的应用效率它的速度效率最少要比CGI 技术提高 5 倍以上它还支持分布式PHP的运算, 即 FastCGI 程序可以在网站服务器以外的主机上执行并且接受来自其它网站服务器来的请求。
FastCGI是语言无关的、可伸缩架构的CGI开放扩展,其主要行为是将CGI解释器进程保持在内存中PHP并因此获得较高的性能众所周知,CGI解释器的反复加载是CGI性能低下的主要原因,如果CGI解释器保持在内存中并接受FastCGI进程管理器调度,则可以提供良好的性能、伸缩性、Fail-Over特性等等PHP。
FastCGI接口方式采用C/S结构,可以将HTTP服务器和脚本解析服务器分开,同时在脚本解析服务器上启动一个或者多个脚本解析守护进程当HTTP服务器每次遇到动态程序时,可以将其直接交付给FastCPHPGI进程来执行,然后将得到的结果返回给浏览器。
这种方式可以让HTTP服务器专一地处理静态请求或者将动态脚本服务器的结果返回给客户端,这在很大程度上提高了整个应用系统的性能FastCGI的工作流程:WePHPb Server启动时载入FastCGI进程管理器(PHP-CGI或者PHP-FPM或者spawn-cgi)
FastCGI进程管理器自身初始化,启动多个CGI解释器进程(可见多个php-cgi)并等待PHP来自Web Server的连接当客户端请求到达Web Server时,FastCGI进程管理器选择并连接到一个CGI解释器。
Web server将CGI环境变量和标准输入发送到FastCGI子进程phPHPp-cgiFastCGI子进程完成处理后将标准输出和错误信息从同一连接返回Web Server当FastCGI子进程关闭连接时,请求便告处理完成。
FastCGI子进程接着等待并处理来自FastCGI进PHP程管理器(运行在Web Server中)的下一个连接 在CGI模式中,php-cgi在此便退出FastCGI 的特点:打破传统页面处理技术传统的页面处理技术,程序必须与 Web 服务器或 ApplicPHPation 服务器处于同一台服务器中。
这种历史已经早N年被FastCGI技术所打破,FastCGI技术的应用程序可以被安装在服务器群中的任何一台服务器,而通过 TCP/IP 协议与 Web 服务器通讯PHP,这样做既适合开发大型分布式 Web 群,也适合高效数据库控制。
明确的请求模式。CGI 技术没有一个明确的角色,在 FastCGI 程序中,程序被赋予明确的角色(响应器角色、认证器角色、过滤器角色)。PHP
WSGI:Python Web服务器网关接口(Python Web Server Gateway Interface,缩写为WSGI)是为Python语言定义的Web服务器和Web应用程序或框架之间的PHP一种简单而通用的接口。
自从WSGI被开发出来以后,许多其它语言中也出现了类似接口WSGI是作为Web服务器与Web应用程序或应用框架之间的一种低级别的接口,以提升可移植Web应用开发的共同点WSGI是PHP基于现存的CGI标准而设计的。
WSGI区分为两个部份:一为“服务器”或“网关”,另一为“应用程序”或“应用框架”在处理一个WSGI请求时,服务器会为应用程序提供环境上下文及一个回调函数(CallbacPHPk Function)当应用程序完成处理请求后,透过先前的回调函数,将结果回传给服务器。
所谓的 WSGI 中间件同时实现了API的两方,因此可以在WSGI服务和WSGI应用之间起调解作用:从WSGI服PHP务器的角度来说,中间件扮演应用程序,而从应用程序的角度来说,中间件扮演服务器“中间件”组件可以执行以下功能:。
重写环境变量后,根据目标URL,将请求消息路由到不同的应用对象允许在一个进程中同时运行多个PHP应用程序或应用框架负载均衡和远程处理,通过在网络上转发请求和响应消息进行内容后处理,例如应用XSLT样式表以前,如何选择合适的Web应用程序框架成为困扰Python初学者的一个问题,这是因为,一般而言PHP,Web应用框架的选择将限制可用的Web服务器的选择,反之亦然。
那时的Python应用程序通常是为CGI,FastCGI,mod_python中的一个而设计,甚至是为特定Web服务器的自定义的API接PHP口而设计的WSGI没有官方的实现, 因为WSGI更像一个协议只要遵照这些协议,WSGI应用(Application)都可以在任何服务器(Server)上运行, 反之亦然。
WSGI就是Python的CGPHPI包装,相对于Fastcgi是PHP的CGI包装WSGI将 web 组件分为三类: web服务器,web中间件,web应用程序, wsgi基本处理模式为 : WSGI Server -> (WSGI PHPMiddleware)* -> WSGI Application 。
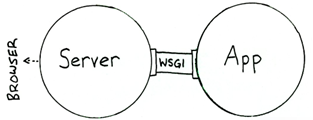
uwsgi:uwsgi协议是一个uWSGI服务器自有的协议,它用于定义传输信息的类型(type of information),每一PHP个uwsgi packet前4byte为传输信息类型描述,它与WSGI相比是两样东西。
据称其效率是fcgi的10倍具体的协议内容请参考:the uwsgi protocol(http://uwsgi-PHPdocs.readthedocs.org/en/latest/Protocol.html)。
以上四者都可以理解为协议!协议!协议!实现了这样的协议,就可以实现Web服务器与Web应用程序相关联的webPHP服务!
uWSGI:uWSGI项目旨在为部署分布式集群的网络应用开发一套完整的解决方案uWSGI主要面向web及其标准服务,已经成功的应用于多种不同的语言由于uWSGI的可扩展架构,它能够被无限制的扩展PHP用来支持更多的平台和语言。
目前,你可以使用C,C++和Objective-C来编写插件项目名称中的“WSGI”是为了向同名的Python Web标准表示感谢,因为WSGI为该项目开发了第一个插件uWSPHPGI是一个Web服务器,它实现了WSGI协议、uwsgi、http等协议。
uWSGI,既不用wsgi协议也不用FastCGI协议,而是自创了上文说将的uwsgi协议uWSGI的主要特点如下:超快的性能PHP低内存占用(实测为apache2的mod_wsgi的一半左右)多app管理详尽的日志功能(可以用来分析app性能和瓶颈)。
高度可定制(内存大小限制,服务一定次数后重启等)。
Gunicorn:和uWSGPHPi类似的工具,从rails的部署工具(Unicorn)移植过来的但是它使用的协议是前文所讲的WSGI,这是python2.5时定义的官方标准(PEP 333 ),根红苗正,而且部署比较简单,详细的使用PHP教程请点击这里(http://gunicorn.org/)。
Gunicorn采用prefork模式,Gunicorn 服务器与各种 Web 框架兼容,只需非常简单的执行,轻量级的资源消耗,以及相当迅速PHP它的特点是与 Django 结合紧密,部署特别方便 缺点也很多,不支持 HTTP 1.1,并发访问性能不高,与 uWSGI,Gevent 等有一定的性能差距。
1. Gunicorn设计GunicornPHP 是一个 master 进程,spawn 出数个工作进程的 web 服务器master 进程控制工作进程的产生与消亡,工作进程只需要接受请求并且处理这样分离的方式使得 reload 代码非常方便,也很PHP容易增加或减少工作进程。
工作进程这块作者给了很大的扩展余地,它可以支持不同的IO方式,如 Gevent,Sync 同步进程,Asyc 异步进程,Eventlet 等等master 跟 worker 进PHP程完全分离,使得 Gunicorn 实质上就是一个控制进程的服务。
2. Gunicorn源码结构从 Application.run() 开始,首先初始化配置,从文件读取,终端读取等等方式完成 confPHPigurate然后启动 Arbiter,Arbiter 是实质上的 master 进程的核心,它首先从配置类中读取并设置,然后初始化信号处理函数,建立 socket。
然后就是开始 spawn 工作进程PHP,根据配置的工作进程数进行 spawn然后就进入了轮询状态,收到信号,处理信号然后继续这里唤醒进程的方式是建立一个 PIPE,通过信号处理函数往 pipe 里 write,然后 master 从 sePHPlect.select() 中唤醒。
工作进程在 spawn 后,开始初始化,然后同样对信号进行处理,并且开始轮询,处理 HTTP 请求,调用 WSGI 的应用端,得到 resopnse 返回然后继续SPHPync 同步进程的好处在于每个 request 都是分离的,每个 request 失败都不会影响其他 request,但这样导致了性能上的瓶颈。
Tornado:Tornado即使一款python 的开PHP发框架,也是一个异步非阻塞的http服务器,它本身的数据产出实现没有遵从上文所说的一些通用协议,因为自身就是web服务器,所以动态请求就直接通过内部的机制,输出成用户所请求的动态内容。
如果把它作为一个PHP单独服务器,想用它来配合其他的框架如Flask来部署,则需要采用WSGI协议,Tornado内置了该协议,tornado.wsgi.WSGIContainer
wsgiref:Python自带的实现了WPHPSGI协议的的wsgi serverwsgi server可以理解为一个符合wsgi规范的web server,接收request请求,封装一系列环境变量,按照wsgi规范调用注册的wsgi app,PHP最后将response返回给客户端。
Django的自带服务器就是它了以上都可以理解为实现!实现!实现!实现了协议的工具!注:mod_wsgi(apache的模块)其实也是实现了wsgi协议的一个模块,PHP现在几乎不废弃了,所以也不多说了,感兴趣的自己查一下吧。
所以如果你采用Django框架开发了应用之后,想部署到生产环境,肯定不能用Django自带的,可以用使用uwsgi协议的uWSGI服务器,也可以PHP采用实现了WSGI协议的gunicorn或者Tornado,亦可以用FastCGI、CGI模式的Nginx、lighttpd、apache服务器。
其他框架亦如此!明白了这些概念在部署的时候就可以做到心PHP中有数,各种工具之间的搭配也就“知其然,并知其所以然”了在我们组的项目中有两种框架Django和Tornado,生产环境也用到了两种部署方式uWSGI和Gunicorn:。
Django项目用NginxPHP+uWSGI方式部署,Tornado项目用Nginx+Gunicorn方式部署:Nginx都作为负载均衡以及静态内容转发Tornado项目用supervisord来管理Gunicorn,用GunicoPHPrn管理Tornado。
众所周知,由于Python的GIL存在,所以Python的并发都采用多进程模式,所以我们部署的方式是一个核心两个进程END● 后台回复【网页特效】,免费获取网页制作特效源码!●PHP 后台回复【电子书】,免费获取python电子书、教程!
●精选10款效果惊艳的HTML5图片特效源码●牛逼啊!一个随时随地写Python代码的神器●推荐4款不错的会员系统登录页面●值得收藏的16个富有PHP创意的HTML5 Canvas动画特效集合推荐↓↓↓

码农那点事儿

觉得我们“好看”的点亮它~
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。