产品经理工作的过程中,要做很多数据分析的工作,如果能够掌握一些常用的Excel运算功能,会对工作效率有所提高。本文总结了一些常用的Excel技能,希望能给你带来帮助。
产品经理的工作过程中常常要做很多数据分析的工作,可能是对产品过往的表现进行总结,也可能是分析市场趋势,又或者是汇报展示中呈现结果等等,这个时候如果能够掌握一些常用的Excel运算功能,往往能极大地提高工作效率,今天就来一起看看吧。
一、数据透视功能介绍:一种快速统计工具,可以快速计算出表中数据的数量信息或求和信息等应用场景:一般用在数据字段很多,而且数据数量(行数)也很多的情况下,可以通过透视的方式快速计算出所需要的结果使用方法:。
选中需要统计的所有数据,必须包含表头在顶部菜单栏选择“插入”,然后在二级菜单中选择“数据透视表”在跳出的弹窗中确认相关细节后,点击确定进入数据透视的页面在右侧的字段列表中选择想要处理的字段内容在右下方透视区域中选择字段所需要的运算方式,最终就可以在左侧表格区域形成所需要的透视表内容。
使用案例:比如下面这个表中,我需要计算各个一级中心已删除存储总量的大小,就可以选中包含一级中心字段和已删除存储字段的列,然后点击插入数据透视表然后在数据透视页面将一级中心作为行透视区的数据,然后将已删除存储量放在值透视区具体选择求和,这样就可以算出各中心已删除存储总量了。
广告胆小者勿入!五四三二一...恐怖的躲猫猫游戏现在开始!×
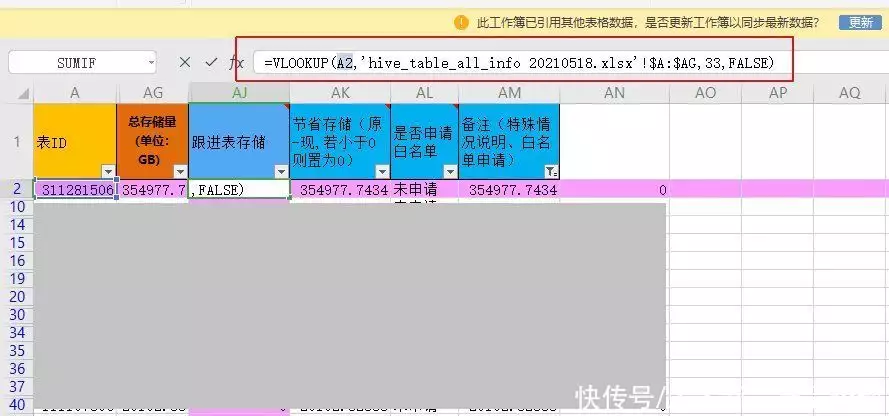
二、Vlookup函数功能介绍:vlookup是一个快速从别的sheet页或者别的表文件中匹配数据的小工具,可以衍生出很多别的功能,是一个使用频率非常高的公式应用场景:一般用在两张表中有相同类型数据需要比较的情况下,来回切换两张表的页面会很麻烦,这个时候就可以用vlookup将数据全部转移到同一张表上然后再做比较。
使用方法:首先需要确认两张表有相对应的字段,这是用来匹配的条件选择其中一张表作为主表,将其他表中需要匹配的内容匹配到主表中观察或计算所用到的公式为“=vlookup(查找值,数据表,列序数,匹配条件)”,需要注意一点是查找值所在字段,要跟数据表的起始列字段一致,这样才能匹配到对应信息。
使用案例:需要对比清单中各个表id对应的存储值变化如图所示在主表中新增一列用来存放匹配值,键入公式“=VLOOKUP(A2,’hive_table_all_info 20210518.xlsx’!$A:$AG,33,FALSE)”其中A2是表id,hive_table_all_info 20210518.xlsx’!$A:$AG是匹配目标表的A列到AG列,33是从匹配目标表的A列开始数的第33列的数值,FALSE代表匹配条件为精准匹配。
最终AJ2这一格中得到的值就是A2这个表id在hive_table_all_info 20210518.xlsx这个表格中对应的数值
广告从秘书起步,十年内无人超越,以一己之力力挽狂澜成就一段传奇×三、Sumif函数功能介绍:用来对指定条件的单元格进行求和应用场景:可以将一列数据中满足某个条件的那些选出来求和使用方法:sumif函数的公式为:=sumif(range,criteria,sum_range),range是条件区域,这里输入的是判定条件所在的区域。
Criteria是求和条件,这里输入的是具体的判定条件,sum_range是求和区域使用案例:例如我们要求的是E列中,数值大于13134的行,对应的AC列 的数值和,那么公式就写成下面这样:=SUMIF(治理清单!E:E,”>13134″,治理清单!AC:AC),如果求的是E列中,数值等于B5格数值的行,对应的AC列的数值和,那么公式就写成下面这样:=SUMIF(治理清单!E:E,B5,治理清单!AC:AC)。
四、Sumifs函数功能介绍:sumifs是sumif的升级版,用来计算多个条件下选定单元格的和应用场景:当我们需要计算同时满足多个限定条件的数据和时,就会用到sumifs的公式,不同条件之间是且的关系,需要同时满足这些条件才会被计算到最终的结果中。
使用方法:sumifs函数的公式为:=SUMIFS(sum_range, criteria_range1, criteria1, [criteria_range2, criteria2], …),sum_rangel还是求和区域,criteria_range1是第一个条件区域,criteria1是第一个条件,后面的以此类推。
使用案例:如下图所示这个公式就是计算,同时满足任务类型是SparkSQL任务、任务状态是上线、节约存储为正数、一级中心为大数据中心这几个条件的节约存储和。公式最终就写成图中红色框线框出来的部分。

五、Countif函数功能介绍:是一个对指定区域满足某个条件的单元格计数的函数应用场景:用在你想要统计符合某个条件的数据数量时,比如你要看一个姓名清单中有几个人是叫张三的、几个人是叫李四的,就可以用这个函数。
使用方法:Countif函数的公式为:“=countif(range,criteria)”,range为需要计数的区域,criteria为需要满足的条件使用案例:例如我们要统计A列中值为“上线”的数据有多少个,那么公式就写作:“=COUNTIF(A:A,“上线”)”回车即可统计出你想要的数据。
六、Countifs函数功能介绍:一个用来统计满足多个条件单元格数量的函数应用场景:需要统计一列数据中同时满足几个不同条件的单元格数量时就会用到这个函数使用方法:Countifs函数的公式为:“=countifs(criteria_range1,criteria1,criteria_range2,criteria2,…)”,criteria_range1是第一个条件所在的单元格区域,criteria1是第一个区域中所需要满足的条件,其形式可以为数字、表达式或文本。
例如,条件可以表示为48、”48″、”>48″或”广州”后面以此类推,各个条件之间是且的关系,需要同时满足才会被计数使用案例:如图所示,当我们需要计算大数据中心,仍然处于上线状态的Hive任务有多少时,就可以输入图中所示的公式,其中治理清单sheet页I列是一级中心列,B6的值是大数据中心,所以第一个条件就是先找出所有大数据中心的数据数量,第二个条件区域M列是任务类型,条件是“Hive任务”,就是找出大数据中心Hive任务的数量,然后第三个条件就是再同时满足上线状态,最后得出的就是我们想要的结果了。
七、If函数功能介绍:条件判断函数应用场景:用在判断一个条件真假的时候,是真的时候返回一个结果,是假的时候返回另一个结果例如判断一个人的性别是不是男的,是男的就显示1,不是男的就显示2使用方法:If函数的公式为“=IF(logical_test,value_if_true,value_if_false)”,其中logical_test是判断条件,value_if_true是判断条件为真时返回的值,value_if_false是判断条件为假时返回的值。
判断条件一般情况下是一个逻辑表达式,比如某个表格内容是否等于某个值,或者大于、小于某个值value_if_true和value_if_false返回的值可以是一个确定的值,也可以是一个别的公式的计算结果。
使用案例:例如下图中这个公式就是判断N2单元格的值是都大于0,如果大于0的话返回的值就是Q2除以N2的结果,如果不是大于0的话返回的值就是0从这个案例中可以看出,这个公式的重点其实是最终返回值,判断条件只是决定最终返回的是哪个值的,并不是核心内容。
八、Iferror函数功能介绍:这是一个用来处理公式中出现错误值的函数应用场景:用在可能计算错误的公式中,当公式计算正常的时候返回值就是公式计算的结果,当公式计算报错的时候就会返回一个其他值使用方法:Iferror函数的公式为:“=IFERROR(value, value_if_error)”,value是检查是否存在错误的公式,value_if_error是检查到错误时返回的值。
使用案例:下图所示的这个公式就是一个iferror的使用案例,当蓝色选中部分的最终计算结果是一个错误值的时候,即运算无法正常进行,出现报错时,整个公式最终的返回值就是0用这个复杂的公式作为案例就是想说明一点,不管这个计算公式有多复杂,最后都要回归到这个简单的判断公式是否正常运算的函数下,只要出错就直接给出一个预先设定好的值。
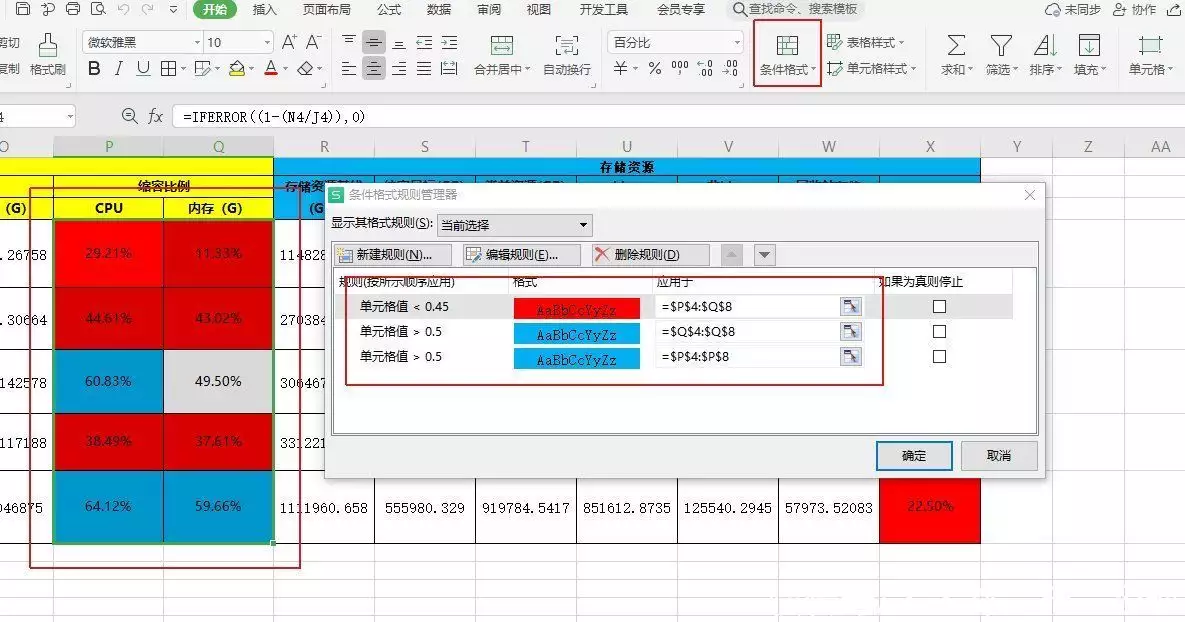
九、条件格式功能介绍:是一个用来给满足某个条件的单元格设置特定格式的工具应用场景:当需要为满足某些条件的单元格设置特定颜色或者特殊字体的时候就可以用条件格式来解决,当然条件格式的功能并不仅限于此,这里只是选其中一种场景。
使用方法:选定需要设置格式的单元格在开始菜单中找到条件格式在条件格式中选中自己要设置的条件类型设置满足条件后单元格呈现的结果使用案例:下图所示,想要单元格内数值超过50%的显示蓝色,不超过45%的显示红色,则可以在条件格式中设置如下内容。
已经设置的规则可以在管理规则中查看
结语:当然了,工具再好也是服务于正确的工作思路的,要处理什么数据首先还是要自己清楚要做什么,然后才能借助工具来解决怎么做的问题就像是武侠小说里的绝世武器,要想发挥作用还是得要在有真功夫的人手上才行作者:多云转晴,公众号:互联网从业笔记。
7年产品经验,C端、B端产品均有涉猎,目前主要从事大数据领域产品工作本文由 @多云转晴 原创发布于人人都是产品经理未经许可,禁止转载题图来自Unsplash,基于CC0协议该文观点仅代表作者本人,人人都是产品经理平台仅提供信息存储空间服务。
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。