
抠图想必大家并不陌生,我们都知道用PS抠图对人脑和电脑都是个体力活,而且相当耗费时间,尤其对一些细腻的东西很难抠的时候,非常的抓狂!那么福利来了,针对这个问题,今天给大家推荐一些免抠图片网站亲测好用!AUTO CLIPPING
https://autoclipping.com/

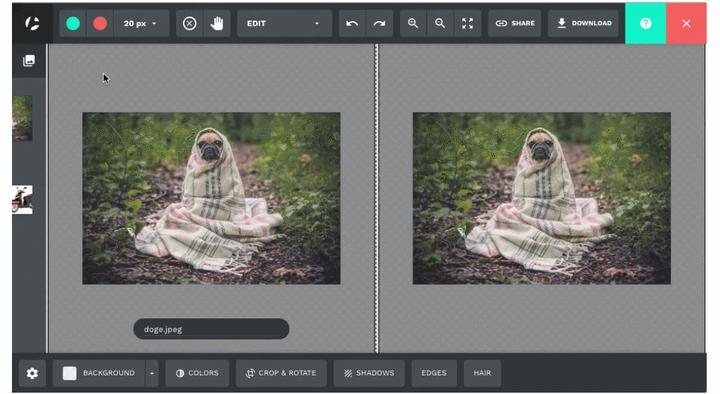
此网站只需上传图片即可手动完成抠图,无需下载其他PC端软件上手简单,操作方便值得一试!当然前期他会有限制次数,后续需要收费5元即可批量处理百张图片!FOTORhttps://www.fotor.com/。

对于很多人来讲,抠图是让人很头痛的一件事情用ps抠出来的图虽然精致,但一不小心,一个下午就过去了因此,为了节约大家做图的时间,Fotor懒设计新开发了一个功能:魔术抠图使用这个功能,你可以将大把时间花在思维创意上,而用不到三秒钟的时间抠一张图。
PHOTO SCISSORhttps://online.photoscissors.com

操作非常简单,红色删除绿色保留黄色头发,只需几步简单的操作即可完成一张抠图,省去大半个小时,最大可支持5M的图片保留!CLIPPING MAGIChttps://clippingmagic.com/
进入Clipping Magic网站后,先上传需要处理的照片等待几秒后就进入处理页面后,左边为原图,右边为效果图右上角选择“+”(绿色)图标,点击图片想保留的元素,选择“-”(红色)图标,点击图片不需要的元素即可剔除。
简单的说就是,哪里需要和哪里不需要就点哪里,就可以获取透明背景图片当然,如果遇到边缘处理不理想的话,还可以用微调工具处理,如橡皮擦、放大缩小功能等进行处理抠图是一个非常有技术含量的东西,对于大部分人来说,这都是一个棘手的问题,但如果你使用了Clipping Magic这个在线工具,那么抠图就变得小菜一碟了。
MALABIhttp://www.malabi.co
Malabi 是一个提供在线版的图片去底色工具,帮助不会PS的用户把图片底色变成透明色,使用在线工具的好处就是无需安装任何插件、扩展、直接上传图片即可自动去背景、去底色!Malabi还提供免费版和收费版,对于普通的用户来说去除简单的底色可以直接上传图片,然后进行微调,跟其他去背景的工具一样,都需要以不同的颜色线条画出来,任何系统会根据画框来计算去除底色的规则,最后达到使用者想要的效果。
不过Malabi只提供免费账号每月 5 张去背照片下载额度,想要更多的话就要参考他们的付费方案,可增加到 20~2000 张不想付费的话,可以多申请几个账号也是不错的方式!LUNAPIChttp://www194.lunapic.com
Lunapic是一个多功能的在线图片编辑器,支持丰富的图片编辑功能,支持多语言版本切换,可以说是一个在线版的Photoshop,用户可以从本地电脑上选择一张图片进行编辑,由于支持中文语言,使用上不存在压力。
功能目前包括裁剪、旋转、镜象、滤镜、漫画、调大小、加边框、加水印等等操作另外你还可以使用它对图片添加各种特效,包括倒影、渐变、电闪/雪花背景效果、动态放大、动态渐变、3D、老电影等几十种效果BONANZA
https://burner.bonanza.com/

此款在线神器相当方便,他和前面这些差不多,绿色显示红色删除,左边原图右边为我们抠出来的图!只需上传图片即可快速抠完同时可以自动从图像中删除背景使图像背景为白色或透明,使用大量高科技软件算法来分析您的图像并检测线条,颜色和焦点,从而将前景中的对象与背景中的对象分开。
变设龙https://www.bslong.cn/#/

这款抠图工具(今天唯一一款国内的工具),每次选择抠图方式之前都有对应的gif演示讲解,分为纯色背景抠图和复杂背景抠图两种背景与主题界线明显的就用纯色背景抠图,只需上传图片,抠图工具自动处理复杂背景抠图情况下,跟上面几种抠图工具一样,需要手动粗选一下删除和保留的区域,其余依旧是工具自动处理。
总体来说发挥比较正常,每张图都扣得干净,体验还算不错!Topaz ReMask 5PS抠图插件需下载,无链接


首先要说明的是这款是个需要下载的插件并非在线网址需要通过动作配合通道和蒙版来实现完美的抠图,像对于一些毛线头发,婚纱,玻璃雾的透明物体,还有树木岩石等复杂物体具有很好的抠图效果,非常适合设计师使用,不仅可以作为插件使用,还可以单独作为软件使用,用它来抠图必定会让你事半功倍。
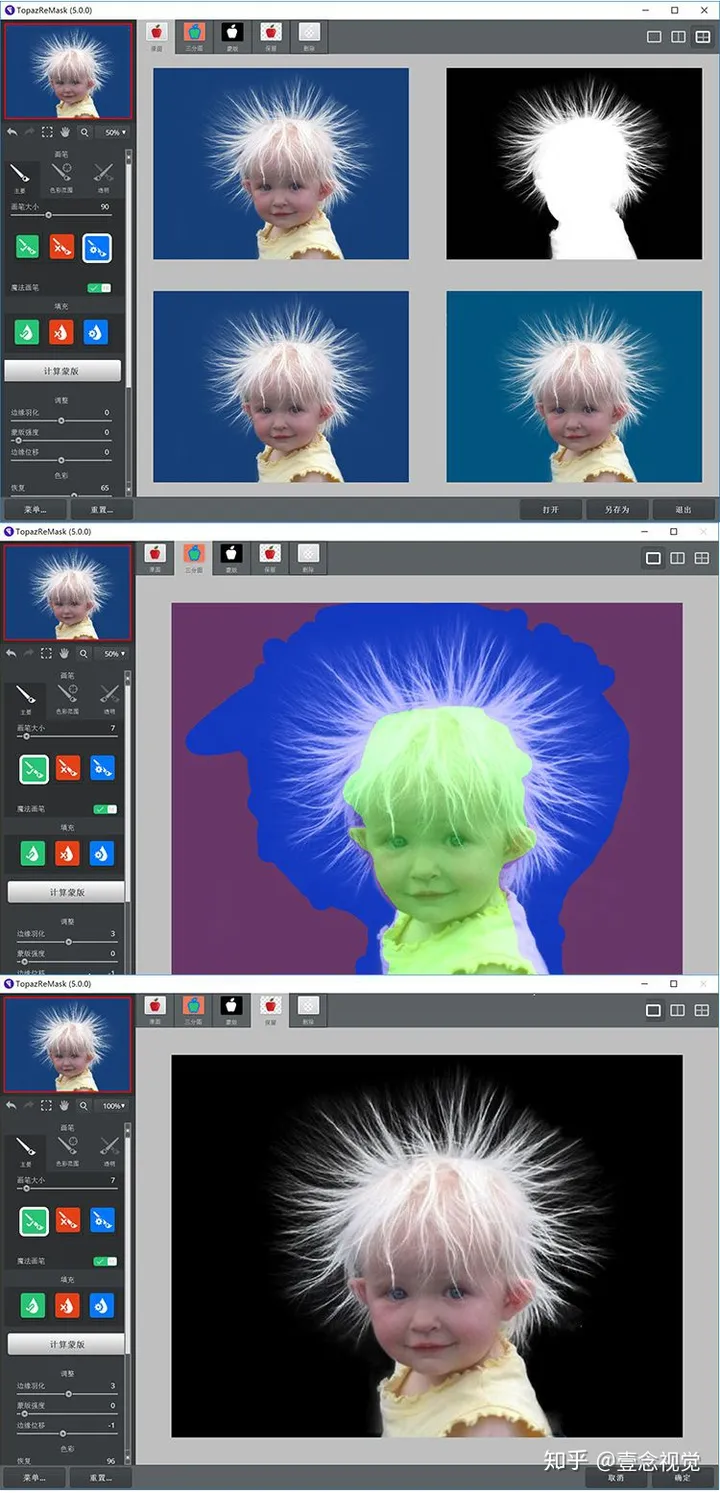
软件特色 - 彩色去污技术帮助解决色斑问题 - 更好的脱毛技术 - 精简工具集,用于微调面具和前景色 - 能够处理某些类型的透明物体 - 复杂对象(如树木和面纱)颜色选择画笔 - 保存和加载三维地图和掩码的能力
- 自动创建图层和自动创建蒙版选项 - 屏幕精度为2屏或4屏因为插件下载链接放文章容易被和谐,所以放在了后台,因此需要在后台回复:抠图领取!总结抠图一直以来是PS的强项,当然也是我们设计师的基本功,但是对于一些门外汉好多人表示望尘莫及,请朋友帮忙难以张口不如自己动手操作,简单方便容易上手何乐而不为!本期抠图出最后一个插件以外均为在线网址,温馨提示,因大部分网站为英文网页,如果点开找不着北,请使用谷歌网页全文翻译功能,推荐使用,OK下期见!
声明:我们只推荐网站的功能,但不代表壹念视觉对此网站的商业行为、交易行为做担保推荐阅读VIP会员招募令2019全新UI教程大礼包14款超好用的PS神级插件UI设计师面试资源大礼包(第一期)UI设计师面试资源大礼包(第二期)。
2019UI设计面试资源大礼包(第三期)UI设计师面试资源大礼包(第四期)设计新人书单推荐(第一期)9本LOGO设计书单推荐(第二期)设计神器终极指南!推荐给设计师看到10部电影推荐迄今为止9个最强大的在线设计神器
关键词回复:VIP、OC、神器、商用字体、UI学习 、面试技巧、Banner、样机下载、LOGO、C4D教程、转手绘、插画、名片、包装、字体下载、2.5D、设计规范,创意合成,作品集模板、商务合作、转载、软件下载请回复相对应缩写(例如:PS)
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。