在日常工作中,我发现周边很多同事,其中不乏研究员和财务,他们对Excel的使用可以说就是大量的重复操作,很多能够使用Excel轻松处理 我的一个风控同事,领导安排他每天统计部门客户交易情况,每天需要从系统导出当天交易情况,然后通过Excel。
频繁的排序、复制和粘贴每天至少花费30分钟才能完成此项工作后来我不经意间看到同事正在马不停蹄的处理数据,我就了解了一下情况,后来我花半天时间,给他写了一个自动执行的VBA代码,大概10秒即可解决问题大大节约了同事的时间,他也有更多的时间做研究或陪伴家人
。

很多小伙伴就要问了,目前还不会使用VBA,那如何提供办公效率呢?其实先用好Excel常用的十大函数就可以大大提高效率,等Excel足够熟悉后,可以尝试写一些VBA代码进一步提高工作效率

对于IF函数,可能很多小伙伴都使用过,尤其做分类的时候一 函数介绍IF 函数可以对值和期待值进行逻辑比较IF 函数最简单的形式表示:如果(内容为 True,则执行某些操作,否则就执行其他操作)。
因此 IF 语句可能有两个结果第一个结果是比较结果为 True,第二个结果是比较结果为 False 一般情况下,IF语句将应用于最小的条件,例如男/女性,是/否等,但有时候可能需要。
嵌套2个及以上的IF函数来解决更复杂的问题 虽然Excel允许嵌套最多 64 个不同的 IF 函数,但不建议这样做原因如下:多个IF语句要求准确的逻辑,保证嵌套的公式100%准确,否则查找错误比较困难。
多个IF语句会变得非常难以维护,特别是输入的时候括号位置不对,也可能出现不同的结果 上面的内容主要来自于Excel自带的帮助文档,可以通过按下F1键获取帮助二 案例讲解 我们经常会需要对。
成绩或绩效等进行分类,下面我将以分数分类进行讲解。
上图中,上部分表格是成绩表,下面一个表格是评分标准,根据学生的成绩进行A、B、C、D和Failed等进行划分 遇到这个案例,我们第一反应肯定想到的就是使用IF函数进行解决,当然。
后期的图文教程会讲解更加方便的方法。敬请期待^_^

通过上图公式,可以看到,我是用了5个IF函数进行嵌套,最后那几个括号对应的也是5个,需要注意不要把位置放错了哦从最简单的嵌套开始,慢慢增加到5层公式:=IF(C2>=90,"A",IF(C2>=80,"B",IF(C2>=70,"C",IF(C2>=60,"D",IF(C2<60,"Failed",)))))。
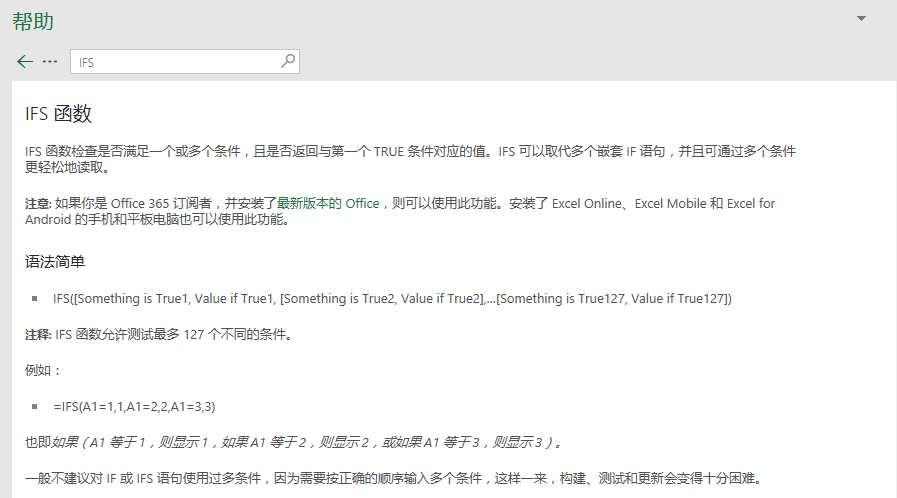
其实呢,微软也觉得自己这个函数太复杂,太容易错误,还不容易检测问题,所以从Office 2016版本(可能需要更新,Office 365最先增加)后,微软出了新的函数IFS官方提示如下(来源于Excel 2016函数IFS帮助):。
注意: 如果你是 Office 365 订阅者,并安装了最新版本的 Office,则可以使用此功能安装了 Excel Online、Excel Mobile 和 Excel for Android 的手机和平板电脑也可以使用此功能。
IFS 函数检查是否满足一个或多个条件,且是否返回与第一个 TRUE 条件对应的值IFS 可以取代多个嵌套 IF 语句,并且可通过多个条件更轻松地读取 知道了IFS函数的工作原理,那么上面的问题就很容易解决了。
看到上面的公式了吗?是不是比前面一个更短更好理解了呢?IFS函数最主要的就是最后需要一个TRUE,这样前面的条件都不满足的时候,就是最后一个Failed啦公式:=IFS(C2>89,"A",C2>79,"B",C2>69,"C",C2>59,"D",TRUE,"Failed")。
三 我的总结 通过上面的讲解,我相信大家对Excel函数IF和其升级版函数IFS都有了一定的了解了。
大家在使用这两个函数的过程中,如果遇到任何问题,可以联系我也可以通过Excel自带的F1帮助进行查找官方的帮助文档可以说是最全的,里面不仅有语法说明,更有案例进行讲解,可以说非常详细的呢。
今天就写到这里吧,希望大家都能熟练使用,提高工作效率^_^微信公众号:SaveUTimeSUT学习交流群:615356012关注公众号,提高效率,节约您的时间!
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。