说起图表,大家头里浮现的图像应该就是excel里自带的那些样式吧,不好看先不说,这些自带的模板也不能很直观的展示数据,这样的图表交给领导显然是不合适的。下面本篇文章给大家推送一篇Excel堆积柱形图图表教程,教你做出不一样的对比柱状图图表,在做工作汇报时惊艳四座。

EXCEL图表大家都知道,类型有很多,柱形图,条形图,折线图和饼图等等。工作中大家做的图表都千篇一律,那如何利用最简单的数据做出一份高大上的图表呢?今天给大家分享一个Excel堆积柱形图对比案例。
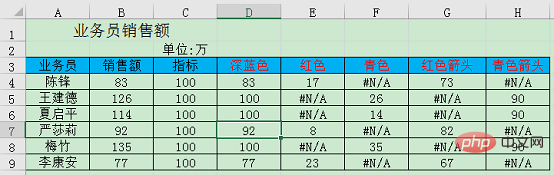
如下图,这是一份公司业务员销售额数据,列出了各业务员的销售额和需要完成的指标。
下图是我们今天要学习制作的图表最终效果。该图表配上箭头清晰的列出了每个业务员是否完成指标的情况,以及和指标的差距。向下的箭头表示低于指标,向上的箭头表示高于指标,这个对比柱状图怎么做的?赶紧学习起来吧!
1.添加辅助列
怎么用Excel做柱状图?首先根据源数据我们要做几个辅助列。这里根据图表系列的颜色来分别跟大家讲解一下各系列的辅助列是如何做的。
深蓝色=IF(B4>=C4,C4,B4) 表示如果销售额大于等于指标,返回指标否则返回销售额。
红色=IF(B4
青色=IF(B4>=C4,B4-C4,NA()) 表示如果销售额大于等于指标,返回差额否则返回空。
那箭头我们怎么做呢?可以设置成折线图的数据标签,减10则是数据标签的位置。
红色箭头=IF(B4
青色箭头=IF(B4>=C4,C4-10,NA()) 表示如果销售额大于等于指标,返回销售额减10否则返回空。
2.插入图表
然后就可以根据辅助列插入图表了。按住Ctrl键,分别选中A3:A9和D3:H9单元格,点击插入选项卡下,插入柱形图-堆积柱形图。
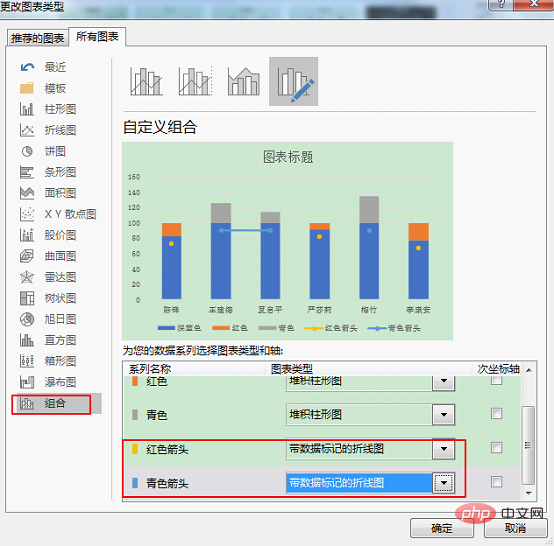
得到图表结果如下。
3.修改图表类型
那现在需要修改红色箭头和青色箭头两个系列的图表类型为“带数据标记的折线图”。
当点击图表的时候,上方选项卡就会出现图表工具,点击图表工具下方设计选项卡里的“更改图表类型”。
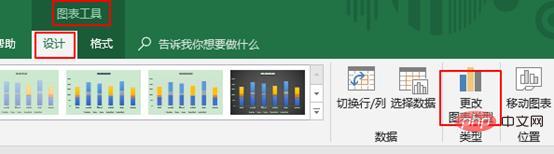
在“更改图表类型”窗口下组合里进行修改。
4.格式设置
4.1 折线图修改无线条
将图表里的折线图有连接线的修改成无线条。
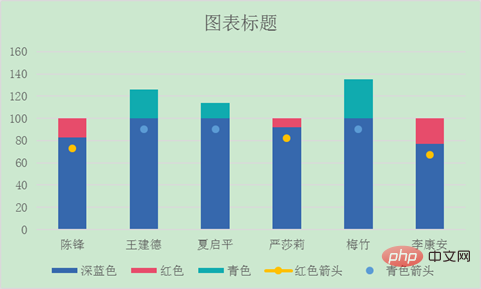
选中有连接线的数据标签,按CTRL+1或者双击,在右侧会弹出“设置数据系列格式”窗口。选择系列选项下的线条—无线条。
4.2 数据系列填充颜色
现在把这个数据系列修改成自己想要的颜色。双击数据系列,在右侧“设置数据系列格式”窗口选择系列选项下的填充—纯色填充,颜色选择为对应的颜色。
修改颜色如下:
4.3 添加箭头
接下来就是把数据标记修改成箭头。点击插入选项卡下,形状—-箭头:下。

双击箭头,在右侧“设置形状格式”窗口,修改箭头颜色和红色系列颜色相同,线条为“无线条”。
点击箭头复制,再点击红色系列的数据标签粘贴。同理,青色箭头可以点击红色箭头复制一个,旋转180度,修改颜色无线条,再在青色系列的数据标签进行复制粘贴。完成如下:
4.4添加数据标签
然后点击红色系列和青色系列,分别点击图表右上方的加号,添加数据标签—居中。
4.5 其他修饰
最后做其他修饰,点击下方的图例,按Delete删除。
双击图表区,在右侧“设置图表区格式”设置颜色,纯色填充。

修改图表标题。最后完成效果如下。
怎么样,大家学会了吗?赶紧下载课件,自己操练起来哟!
相关学习推荐:excel教程
以上就是Excel图表学习之实际和目标对比的柱状图的详细内容,更多请关注php中文网其它相关文章!






发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。