最近在做PHP接口的性能优化,在排查性能问题和优化的过程中总结了一些心得,分享给大家性能问题排查首先,做性能优化要先进行性问题排查,即排查PHP接口的代码实现中那一块执行比较慢排查方法一笔者使用的ThinkPHP框架中自带了G方法可以很方便的获取某个区间的运行时间和内存占用情况。
例如:G(‘begin’);// …其他代码段G(‘end’);// …也许这里还有其他代码// 进行统计区间echo G(‘begin’,‘end’).‘s’;//输出代码运行时间echo G(‘begin’,‘end’,‘m’).‘kb’;//输出内存开销统计(单位为kb)
通过对不同代码片段的运行时间统计与接口总运行时间的对比,可以分析出哪块代码的运行存在性能问题,然后再针对性的排查排查方法二使用PHP性能分析工具来辅助定位目前市面上有很多PHP性能分析工具,老牌的调试工具XDebug,以及Facebook开源的Xhprof。
以Xhprof举例,配置成功后,可以记录和生成函数的调用链图,包含每个函数的请求次数、阻塞时间、CPU时间和内存使用情况
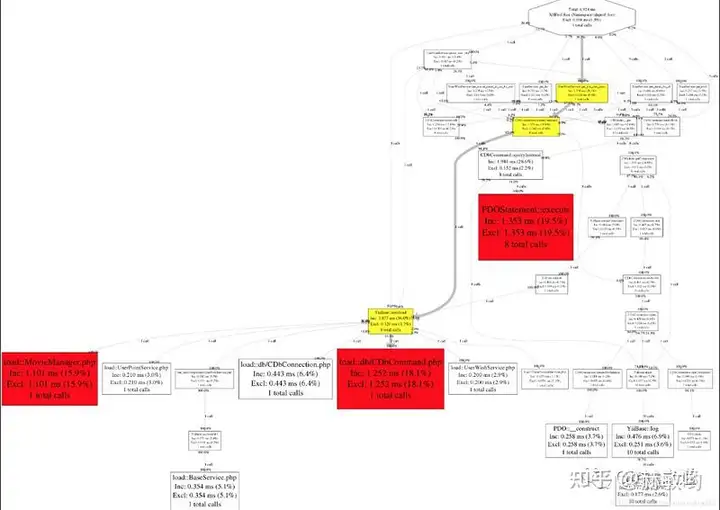
1080×766 68.3 KB图中标记为红色或黄色的区域就是需要重点关注的地方性能问题解决通常在工具的辅助下,性能问题排查相对来说还是比较简单的比较有挑战的是如何解决这些性能问题笔者在解决性能问题的过程中也做了一些解决方式的总结:。
一. 代码层面代码的风格因人而异,实现方式也非常灵活两个人实现同样的查询列表功能,代码写法都会不同以下几点是我个人总结的代码性能避坑指南:1. 使用PHP7+版本PHP7发布的时候号称比PHP5.6快两倍,而最新的PHP 7.3比PHP 5.6快3倍!所以升级PHP版本的收益还是很大的。
1. 尽量减少循环嵌套写法循环嵌套增加所带来的运行消耗是指数级的例如第一层循环执行100次,第二层循环执行100次,第三层循环执行100次,那么最终循环的运行次数就是100100100 = 一百万次所以要尽量减少循环的嵌套。
1. 尽量减少数据库操作,例如避免在循环中进行数据库查询数据库操作是比较消耗性能的动作,如果可以尽量少的做数据库操作,性能会有很大的提升 1. 尽量将对象的声明写在循环外部以减少声明次数 1. 使用unset()及时释放不使用的变量尤其是大数组,以便释放内存。
1. 方法尽量静态化静态方法在程序开始时生成内存,实例方法在程序运行中生成内存,所以静态方法可以直接调用,实例方法要先成生实例,通过实例调用方法,静态速度很快,但是多了会占内存 1. 尽量少用正则表达式。
正则表达式的开销大,使用起来简单,但是性能低因为正则表达式需要回溯;正则表达式越长,回溯的开销越大,优化正则表达式是需要技术水平的,正则技术不达标,不要乱用正则 1. 使用单引号在php中,单引号和双引号是有区别的,作为一种习惯字符串我都用单引号,因为它无需编译。
二. 数据库层面1. sql查询优化排查问题过程中,会发现很多性能的瓶颈在于复杂sql的查询太慢我们可以使用‘EXPLAIN ’关键字来分析复杂sql的运行慢的原因将‘EXPLAIN’加在sql语句开始的位置,就能分析出这条SQL语句的执行计划,查看该SQL语句有没有使用索引,有没有做全表扫描等等。
例如:EXPLAIN select * from person where dept_id =(select did from dept where dname =‘python’);概要描述:- **id**: 查询序列号,代表执行的先后顺序。
- **select_type**:表示查询的类型例子中的primary和subquery分别代表最外层查询和子查询- **table**:显示这一步所访问数据库中表名称- **type**:表示查询计划的连接类型。
例子中的ALL代表MySQL将遍历全表以找到匹配的行,没有使用任何索引这时就说明需要加索引进行优化了性能由好到差:null > system/const > eq_ref > ref > ref_or_null >index_merge > range > index > all;如果有类型是 ALL 时,表示预计会进行全表扫描(full table scan)。
通常全表扫描的代价是比较大的,建议创建适当的索引,通过索引检索避免全表扫描- **possible_keys**:指出MySQL能使用哪个索引在表中找到记录,查询涉及到的字段上若存在索引,则该索引将被列出。
- **key**:显示MySQL实际决定使用的键(索引),必然包含在possible_keys中- **key_len**:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度不损失精确性的情况下,长度越短越好。
- **ref**:列与索引的比较,表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值- **rows**:估算出结果集行数,表示MySQL根据表统计信息及索引选用情况,估算的找到所需的记录所需要读取的行数。
- **Extra**:该列包含MySQL解决查询的详细信息如果有出现 Using temporary 或者 Using filesort 则要多加关注:- **Using temporary**,表示需要创建临时表以满足需求,通常是因为GROUP BY的列没有索引,或者GROUP BY和ORDER BY的列不一样,也需要创建临时表,建议添加适当的索引。
- **Using filesort**,表示无法利用索引完成排序,也有可能是因为多表连接时,排序字段不是驱动表中的字段,因此也没办法利用索引完成排序,建议添加适当的索引- **Using where**,通常是因为全表扫描或全索引扫描时(type 列显示为 ALL 或 index),又加上了WHERE条件,建议添加适当的索引。
2. 分库分表基本思想就要把一个数据库切分成多个部分放到不同的数据库(server)上,从而缓解单一数据库的性能问题要做分库分表之前,首先要思考一个问题:MySQL 单表数据达到多少时才需要考虑分库分表?网上流传的文章有的说几千万行,有的说几百万行,都没有一个准确的数字。
阿里巴巴《Java 开发手册》提出单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表由于笔者所要优化的数据库单表还达不到这个量级,所以没有进行分库分表的实际操作但是笔者又深入探索了一个问题:这个500W是怎么推算出来的?。
事实上,这个数值和实际记录的条数无关,而与 MySQL 的配置以及机器的硬件有关因为,MySQL 为了提高性能,会将表的索引装载到内存中InnoDB buffer size 足够的情况下,其能完成全加载进内存,查询不会有问题。
但是,当单表数据库到达某个量级的上限时,导致内存无法存储其索引,使得之后的 SQL 查询会产生磁盘 IO,从而导致性能下降当然,这个还有具体的表结构的设计有关,最终导致的问题都是内存限制所以,如果增加硬件配置,可能会带来立竿见影的性能提升。
三. 硬件配置这种方式不用多介绍了线上压力顶不住的时候,通常都会立即加机器加配置来抗久而久之,很多开发人员对加机器加配置产生了依赖虽然增加硬件配置是最简单粗暴的解决方案,但是作为有追求的技术人员,还是要多从代码层面和数据库层面做深度优化。
所以这条解决方案笔者放在最后推荐大家使用



发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。