如何录制电脑内部声音?不管是娱乐圈还是现实生活,【录音】这个功能的重要性不言而喻而电脑录音已在影视配音、音视频剪辑、会议记录、在线教育等多个领域发光发热!本文将为您推荐8款电脑录音软件,并详细介绍电脑录音的多种方式、所需设备、系统自带录音功能的使用方法,以及录制效果的评价!诚意满满的全方面测评教程!赶紧点赞收藏,电脑录音这一块,不谦虚的说,我已经是专业测评。
博主了!第一!你知道电脑录音有多少种方式吗?总是看一堆测评电脑录音软件、声卡测评,却不知道电脑有几种录音方式?OUT!我们目前使用电脑一般有以下3种录音方式:◉▥◉状元:系统自带录音Windows系统自带“录音机”应用,支持简单的录音功能。
□▫□榜眼:第三方软件录音使用以下推荐8款电脑录音软件,可实现更高质量的录音和更丰富的编辑功能。◂◈▸探花:录屏软件录音部分录屏软件也具备音频录制功能,方便用户同时录制屏幕和声音。

第二!你知道电脑录音需要什么设备吗?Ⅰ录音话筒:推荐使用电容话筒,以获得更好的录音效果同时,防喷罩等配件也是必不可少的Ⅱ调音控制台:传统型的模拟调音台适合初学者使用,用于音频的放大、修饰等操作Ⅲ声卡:声卡是决定音乐质量的关键之一,建议选择有知名度、有保障的品牌。
Ⅳ监听设备:一套好的监听设备能帮助您更好地听出音频的优缺点,从而完成高质量的作品。

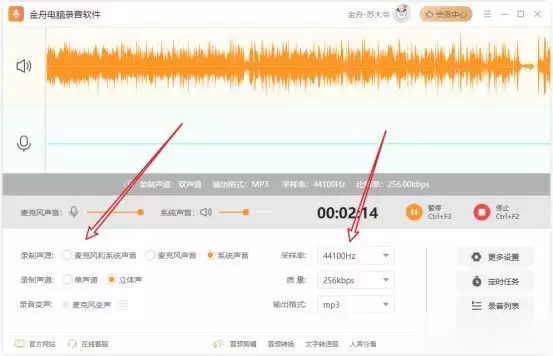
第三!你知道电脑录音有哪些好评的录音软件吗?➊金舟电脑录音软件:一款Windows专业录音软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V3.7.21. 金舟电脑录音软件适用于Windows系统,支持多种录制模式,如系统声音和麦克风声音
的同时录制,或单独录制。2. 可以手动设置录音快捷方式、录音参数调整。3. 录制的音质清晰流畅,支持多种录音格式转换。操作简便,适合配音等需求。使用评分:评分:4.8/5
➋Audacity:一款免费开源电脑录音软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V3.6.01. Audacity是一款在linux下发展起来的,遵循GNU协议的免费跨平台软件。
是一个易用、多轨音频录制和编辑的自由、开源、音乐软件可以在Windows,MacOS X,GNU/Linux和其他操作系统上使用2. 提供复杂的音频处理和编辑功能,如录音、去噪、音频分割等3. 适合专业音频处理需求。
Audacity只有英文版本,对于小编这个英语小白来说,使用起来有些不方便。使用评分:4.5/5
➌Adobe Audition:一款专业级Adobe音频处理软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V2022 22.6.0.661. Adobe Audition是一款专业级的录音软件,支持多通道录制、混音、同时处理多个音频轨道等强大功能。
2. 支持多轨录音和实时音频处理,适合专业音频制作和后期处理。3. 适合专业音频工作选手。另外Adobe Audition使用起来需要一定的学习成本和电脑硬件支持运行。软件评分:4.7/5

➍MakeAudio录音软件:一款实用的录音剪辑软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V1.0.0.0MakeAudio是一款功能强大的音频处理软件,整合了录音、剪辑、转换和管理等多种实用工具。
对于经常使用录音的用户来说,除了语言不太方便,值得推荐!软件评分:4.0/5

➎Ableton Live:一款实时录音软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V11.3.21Ableton Live支持实时音频和MIDI录音、编曲和表演软件,专业性强,适合有一定基础的用户。
软件评分:4.2/5
➏Cockos REAPER:一款海外热门录音软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V7.11Cockos REAPER是一款在国外知名的录音软件,以其灵活性、高效性和可扩展性而著称,是许多专业音频制
作者的首选。Reaper还支持许多第三方插件,可以根据不同需求进行定制化配置。同样是海外版产品,语言是一大硬伤。软件评分:4.1/5分
➐金舟录屏大师:一款支持录制电脑内部声音的录屏软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V4.1.01. 金舟录屏大师除了屏幕录制功能外,还支持专业的音频录制模式,可输出多种格式的音频文件,并支持录音后的简单
编辑。2. 功能丰富,支持多种录制模式,实现录屏录音同步操作。
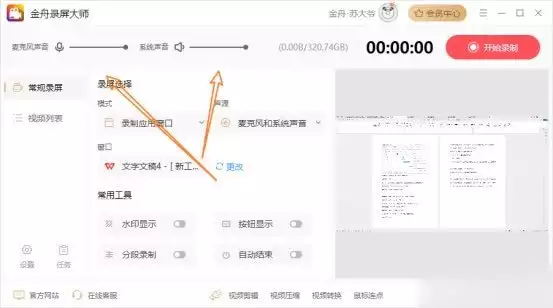
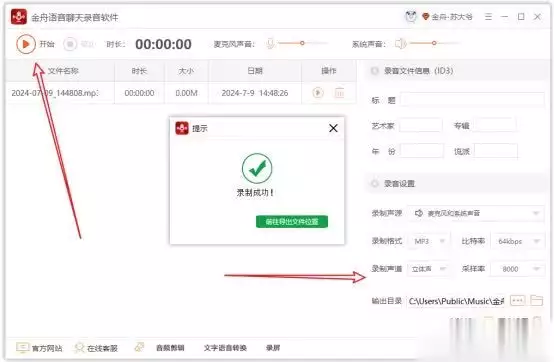
➑金舟语言聊天录音软件:一款支持通话的电脑录音软件硬件型号:HUAWEI MateBook D14系统版本:Windows 11软件版本:V4.3.31.金舟语言聊天录音软件是一款支持高品质录音软件,允许用户选择声音来源和保存格式,操作简便,适合多种录音场景。
2. 操作简单,支持高清录制和无损音质。
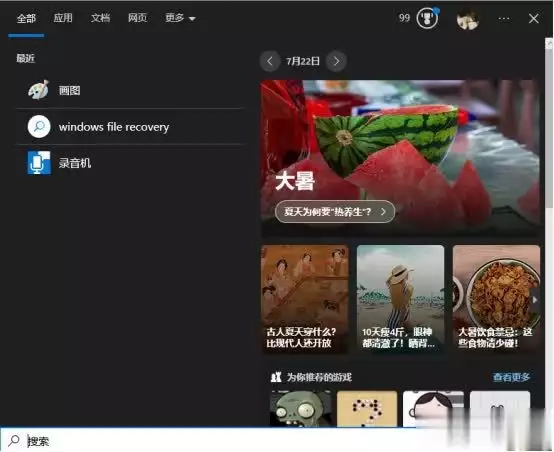
第四!你知道电脑自带的录音功能使用方法吗?以Windows系统为例,让我们用详细的操作步骤告诉你,电脑自带的录音软件到底是如何开启的!步骤1:按下快捷键【win+S】调出应用搜索框,输入【录音机】并打开应用。
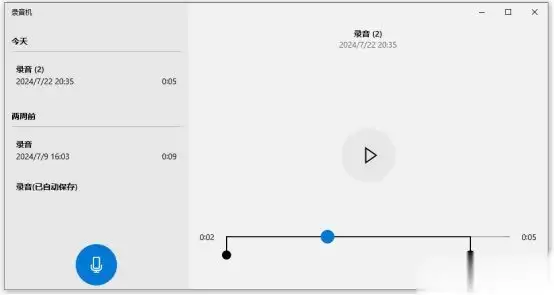
步骤2:连接麦克风后,点击开始录制即可。

但请注意,系统自带录音功能可能无法单独录制系统声音或麦克风声音。
五、录制效果评价不同的录音软件和设备会产生不同的录制效果。一般来说,专业级的录音软件和高质量的录音设备能够产生更清晰、更流畅的音频效果。而系统自带录音功能虽然方便,但可能在音质上有所欠缺。

六、推荐本地和在线录音软件本地录音软件如金舟电脑录音软件、Audacity等适合长期存储和编辑大量音频文件的用户而在线录音软件如“录音全能”等则适合临时录音或需要快速分享录音文件的用户具体选择取决于您的使用场景和需求。
以上就是关于电脑录音软件的推荐和全攻略。希望对您有所帮助!
亲爱的读者们,感谢您花时间阅读本文。如果您对本文有任何疑问或建议,请随时联系我。我非常乐意与您交流。


发表评论:
◎欢迎参与讨论,请在这里发表您的看法、交流您的观点。